AWS DMS CDC from SQL Server to S3 Using CDK – Pipeline Guide
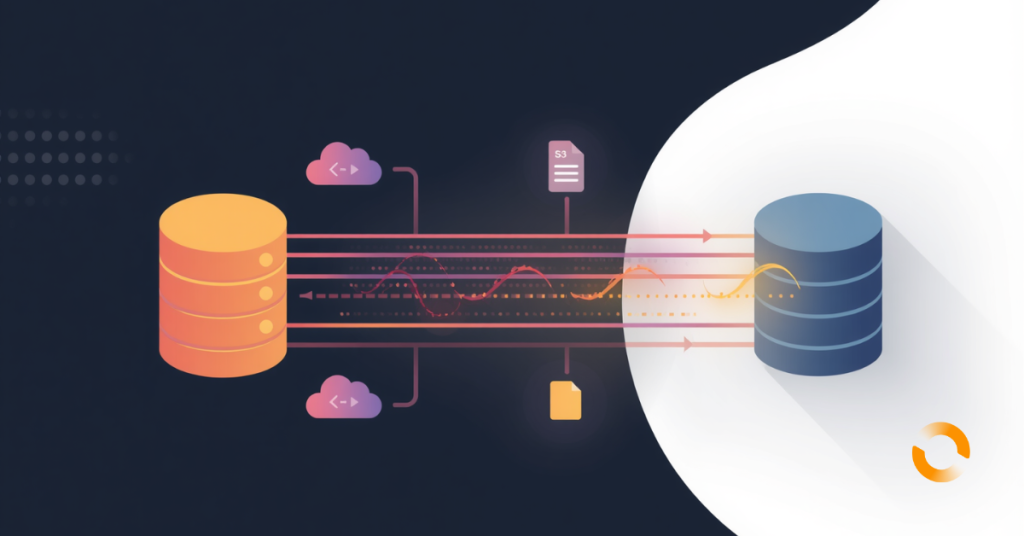
Learn how to use AWS DMS CDC to replicate SQL Server data to S3 in near real time using AWS CDK. This step-by-step guide covers full load, continuous change data capture, table mapping, IAM configuration, and best practices for building a robust, production-ready data ingestion pipeline.
AWS CDK vs Terraform vs CloudFormation: Building a Real AWS Project

Comparing AWS CDK vs Terraform vs CloudFormation? This guide breaks down the strengths, weaknesses, and best use cases of each Infrastructure as Code (IaC) tool on a large AWS project. Learn how to choose the right AWS IaC tool for your team, reduce complexity, and improve deployment speed with practical, experience-based insights.
dbt Core vs dbt Platform: Modern Data Transformation with dbt (Part 1)

dbt Core and the dbt Platform use the same transformation engine but differ in deployment, governance, and operational approach. This blog explores where dbt fits in the modern data stack, the strengths of each option, and how teams can choose the right solution based on size, maturity, and workflow requirements.
On-Demand dbt Execution: Rethinking Analytics Engineering in Secure Cloud Environments

In secure enterprise cloud environments, traditional dbt deployment models can introduce unnecessary cost, security risk, and operational friction. This blog explores an on-demand, containerised dbt execution model that treats dbt as an ephemeral workload rather than a long-running service. Orchestrated with AWS MWAA and backed by ECS Fargate, the approach enables scalable, secure analytics transformations while improving cost efficiency, data quality observability, and CI/CD integration in modern enterprise data lakes.
Transforming Data Engineering with DevOps on the Databricks Platform

The role of the Data Engineer is rapidly changing, from writing ETL scripts to engineering production-grade data products. On the Databricks Lakehouse Platform, this shift demands more than technical know-how; it requires a DevOps mindset. By embracing software engineering best practices, automated testing, and CI/CD pipelines, data teams can deliver scalable, reliable, and secure solutions. This blog explores how DevOps principles and tools like Git Folders and Databricks Asset Bundles are transforming data engineering into a discipline of continuous innovation and delivery.
Data Strategy Diagnostic: Building a Robust Data Strategy on AWS

Data is everywhere but without a clear strategy, it can hold your business back instead of moving it forward. In this blog, we share how the AWS Data Strategy Diagnostic helps organisations assess their data maturity, uncover gaps, and build a practical roadmap to turn data into real business value.
Prioritising Data Quality with dbt-expectations: A Practical Approach to Building Reliable Data Pipelines

Discover how dbt-expectations enhances data quality checks within dbt pipelines, ensuring reliable analytics and streamlined workflows.
Supercharge your Data Validation: Using CTEs and Pandas to seamlessly compare CSV data with Postgres RDS
Learn to use CTEs and Pandas to efficiently compare CSV data with a PostgreSQL database without loading all data into memory.
Serverless Solution for RDS Granular Database Backup – Part 1

This blog explores a serverless AWS solution designed to address the challenges of conducting efficient granular backups of RDS databases, offering insights into its architecture and benefits.
Retrieval Augmented Generation (RAG) Options in AWS

Cevo Consultant JO Reyes explores options for building Generative AI applications using Amazon Web Services (AWS).