Modern data foundations for AI: The strategic imperative for AI at scale

As organisations race to adopt generative and agentic AI, many are discovering a hard truth: AI ambition is only as strong as the data platforms that underpin it. Legacy SQL Server and Oracle environments were never designed to support the scale, integration, and velocity modern AI demands. This article explores why modern data foundations are now a strategic imperative for enabling AI at scale.
Metadata-Driven PII Masking in dbt on AWS Glue

Learn how to implement PII masking in dbt on AWS Glue using a metadata-driven approach powered by Jinja macros and post-hooks. This guide shows how to protect sensitive data in non-production environments without modifying model SQL, using Spark SQL and Iceberg tables for scalable, deterministic masking.
AWS DMS CDC from SQL Server to S3 Using CDK – Pipeline Guide
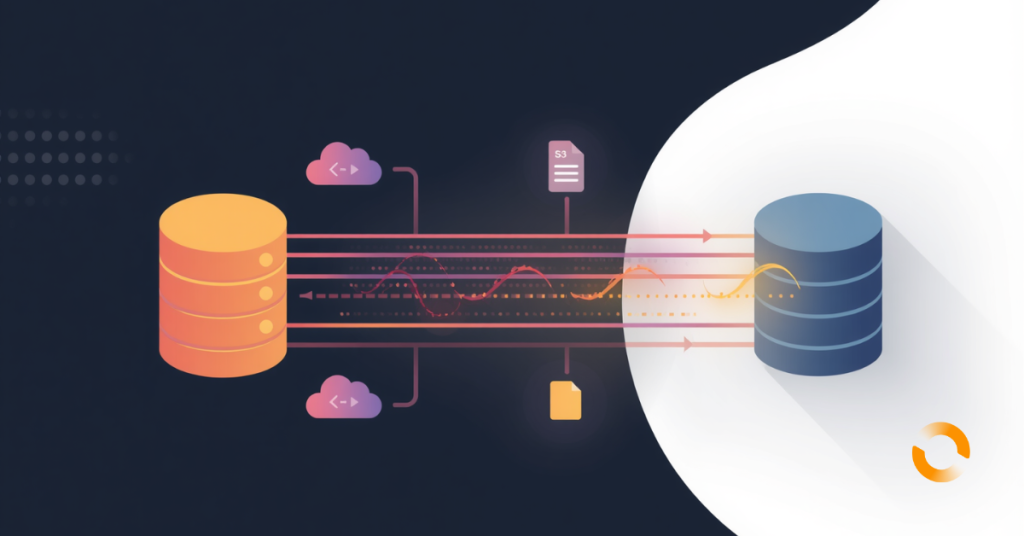
Learn how to use AWS DMS CDC to replicate SQL Server data to S3 in near real time using AWS CDK. This step-by-step guide covers full load, continuous change data capture, table mapping, IAM configuration, and best practices for building a robust, production-ready data ingestion pipeline.
AWS Vector Store for RAG – Beyond OpenSearch

Compare AWS vector store options for RAG, including OpenSearch, S3 Vectors, Aurora pgvector, and more. This guide breaks down Bedrock Knowledge Bases integrations and custom pipeline approaches to help you choose the right solution based on latency, cost, and architecture.
AWS CDK vs Terraform vs CloudFormation: Building a Real AWS Project

Comparing AWS CDK vs Terraform vs CloudFormation? This guide breaks down the strengths, weaknesses, and best use cases of each Infrastructure as Code (IaC) tool on a large AWS project. Learn how to choose the right AWS IaC tool for your team, reduce complexity, and improve deployment speed with practical, experience-based insights.
dbt Core vs dbt Platform: Modern Data Transformation with dbt (Part 1)

dbt Core and the dbt Platform use the same transformation engine but differ in deployment, governance, and operational approach. This blog explores where dbt fits in the modern data stack, the strengths of each option, and how teams can choose the right solution based on size, maturity, and workflow requirements.
On-Demand dbt Execution: Rethinking Analytics Engineering in Secure Cloud Environments

In secure enterprise cloud environments, traditional dbt deployment models can introduce unnecessary cost, security risk, and operational friction. This blog explores an on-demand, containerised dbt execution model that treats dbt as an ephemeral workload rather than a long-running service. Orchestrated with AWS MWAA and backed by ECS Fargate, the approach enables scalable, secure analytics transformations while improving cost efficiency, data quality observability, and CI/CD integration in modern enterprise data lakes.
Cevo’s adoption of the AWS EBA Framework for our clients

Digital transformation often stalls between strategy and execution. AWS Experience-Based Accelerators give organisations a safe, hands-on way to test cloud, modernisation and AI initiatives before committing to scale. Learn how Cevo delivers partner-led EBAs that turn experience into confidence, and confidence into action.
Enhance Kubernetes Cluster Performance and Optimise Cost with Karpenter – Part 3

Discover how Karpenter enhances Kubernetes cluster performance and optimises costs in EKS. Learn how to monitor Karpenter using logs, metrics, and dashboards to gain full observability, identify scaling bottlenecks, and fine-tune your workloads for reliable, cost-efficient operations.
Enhance Kubernetes Cluster Performance and Optimise Cost with Karpenter – Part 2

Learn how to migrate from Kubernetes Cluster Autoscaler to Karpenter on Amazon EKS to improve scaling speed, reduce infrastructure costs, and increase resource efficiency. This deep dive also explores EKS Auto Mode, showing how cloud-managed autoscaling can further reduce operational overhead while improving security and reliability.