“Business continuity and IT resilience are a click away with CloudEndure Disaster Recovery.” That’s the marketing line, but as you would expect, in reality there is probably more to the story.
As with any Business Continuity or Disaster Recovery solution, there needs to be a great deal of planning, process development, and testing, regardless of what technical solutions may be used. This post outlines various considerations for the operation of a DR solution in AWS using CloudEndure based on recent DRaaS work carried out for a customer.
What does CloudEndure do for you?
CloudEndure Disaster Recovery provides continuous block level replication of your machines’ disks into a low-cost staging area in your target AWS Account and Region. The lower cost comes about as only the disk storage is replicated and equivalent compute resources are only launched at the time of a recovery. In the event of an unexpected outage, data corruption, or malicious attack, you can instruct CloudEndure to launch copies of your machines in their fully provisioned state in minutes, minimising RPOs and RTOs.
The diagram below illustrates a typical deployment architecture:

This architecture is broken up into 4 key domains:
- Source machines which require DR protection; these may be physical servers or VMs typically hosted on-premise or in managed data centres.
- Staging area where replicated disk images are maintained; hosted in your chosen AWS account and region, a target subnet includes CloudEndure replication servers and an EBS volume per protected source disk/volume.
- Target network where new services will be launched in the case of a DR, hosted in the same AWS account and region as the staging area
- The CloudEndure Console which is the tool’s control plane, managing and orchestrating assets on your behalf.
All of this is good in theory, but all systems are different and all environments have hidden gotchas that are likely to spring out and impact your efficiency and timeline. Through our recent delivery of a CloudEndure solution we have identified a number of areas where increased consideration and planning are well worth the investment.
CloudEndure Considerations
Network connectivity
For this whole thing to work, a stable, secure and low latency connection is required between the protected workloads and AWS. If not already in place you need to look at establishing this connection using either Direct Connect or Site-toSite VPN. This connection is required for replication traffic to the AWS staging area and from the AWS target area back to on-premise for failback (as illustrated below). When deciding on what connectivity is most suitable, you need to consider both replication requirements and operational communication requirements to ensure the capacity and availability meets your needs.
In addition, CloudEndure on-premise agents and/or virtual appliances do require Internet connectivity, either directly or via proxy servers, to communicate with the CloudEndure Management Console. However, many existing data centers are not configured to have hosts access the Internet, not even via a proxy. There may be a significant effort required to establish this connectivity, and security policy exemptions may need to be agreed.
Replication Traffic
An important consideration for a successful DR solution using CloudEndure is the bandwidth requirement of the replication link. In order for CloudEndure to maintain continuous replication of your protected workloads the replication link must have bandwidth at least equal to the total average writes to all your protected volumes.
For example, if you are aiming to protect 50 servers each writing an average of 20GB to disk per day you need to take it into account when calculating bandwidth as follows: 1000GB/day –> ~100Mbps. The amount of bandwidth required may lead to consideration of a dedicated link for replication traffic. If bandwidth is insufficient, or the connection fails, replication will start to lag, and this has an impact on your RPO as you will need to recover to an earlier point in time in the event of a failover.
Additionally, appropriate planning also needs to be done on the network routes and required traffic for reverse replication needed to enable failback to normal operation. The below diagram illustrates the additional access required directly between the source and target areas to facilitate this.
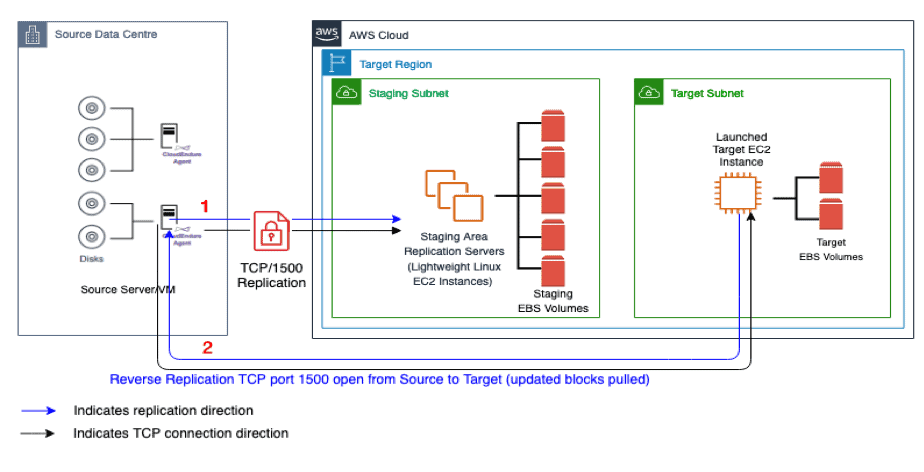
Host Based Agent or Appliance
CloudEndure Disaster Recovery can be implemented on the source infrastructure either as a host based agent installed on each protected server, or in the case of VMWare environments as a virtual appliance. Careful consideration should be given to which approach is best for your environment, or maybe both will be required for different machines.
Host based agents:
- allow physical servers to also be protected in addition to virtual machines
- simple installation but will need to be repeated for every protected server
- every protected server will need Internet access either directly or via a proxy server for communication with the CloudEndure Console
- failback is a manual process which requires the on-premise server to be booted using a Failback Client ISO in order to establish reverse replication.
Virtual appliance:
- will only protect VMWare virtual machines
- more complex installation but far fewer installs required
- appliance requires significant vSphere permissions to operate
- only the virtual appliance requires connectivity to the CloudEndure Console
- orchestration of failback is possible.
Retain IP or Change IP
When configuring launch blueprints in CloudEndure for your protected workloads you may choose to retain the same IP in the DR target environment or use different IP addresses. Each approach has advantages and disadvantages – if you retain existing IP addresses then the failover process will require both routing changes and entire subnets being failed over together, it also may require careful planning of failback.
On the other hand, changing IP addresses in the DR environment may require firewall changes for east-west traffic, DNS changes, and potentially application changes if IP addresses are hard-coded in any components. Some of these changes can potentially be automated through scripting but don’t under-estimate the effort involved in doing so.
AWS Target Considerations
These items are essential in order for failed-over workloads to function in your AWS target location. In the absence of appropriate implementation of solutions for these items, AWS based workloads may not be able to communicate with on-premise services required for normal functionality.
Name Resolution - Hybrid DNS
You will find that in the absence of appropriate DNS configuration that failed-over workloads will be unable to resolve addresses for resources in the on-premise network. This may prevent communication with on-premise servers such as domain controllers and prevent required application communications.
It is necessary therefore to configure an appropriate hybrid DNS solution, as an example the DR account could be configured with the AWS Route53 Resolver service to forward lookup requests for on-premise resources to the on-premise domain controllers.
Active Directory Connectivity
For Windows based workloads to function correctly in your AWS target it is essential that these servers are able to communicate with relevant domain controllers. In the absence of this logins on AWS based domain joined servers could be impacted.
At a minimum, network connectivity is required that ensures these workloads are able to communicate with the on-premise domain controllers. Extension of on-premise domain services into AWS should also be considered – AWS Managed Microsoft AD is one potential solution to achieve this.
Routing/Connectivity
Apart from the decisions made related to CloudEndure replication connectivity, and whether IP addresses will be retained or changed when launching recovery instances, consideration needs to be given to the overall network connectivity of failed over workloads with other services, both on-premise and external. Solutions for these requirements may involve routing, firewall, proxy, and other network configuration changes depending on the location of the services during a DR event.
It is also important to consider Internet connectivity of the AWS target subnet, is it a requirement that connectivity to external services continue to utilise existing controlled egress points or will direct external connectivity be permitted.
Identity and Access Management (IAM)
Will there be a requirement for AWS recovery instances to access AWS services while operating in DR? For example, will post-launch scripts need to access objects from S3 for installing tools required in AWS, or to perform additional network configuration?
Access can be provided to the instances through the application of IAM roles with appropriate permissions, and allocated through the machine blueprints in CloudEndure.
Operational Considerations
A number of items may need to be considered for the CloudEndure DR solution to meet your organisation’s architectural and security requirements. In the absence of appropriate implementation of solutions for these items, AWS based workloads may provide normal application functionality but would likely not meet organisation standards.
Existing Operations Services
Consideration must also be given to solving for any connectivity issues for existing operations services provided either on-premise or through SaaS offerings. These would likely include such items as Endpoint Protection, Vulnerability Management, Monitoring, Time Synchronisation, and Centralised Logging.
Based on how these services are provided, connectivity to management endpoints will need to be solved in the AWS target environment if it is decided that these services are still relevant while the workloads operate in AWS. An alternative may be to look at alternative cloud native solutions to delivery of these services in AWS.
Continuity of Backups
It is most likely that your organisation operates an enterprise backup solution for on-premise infrastructure. When considering CloudEndure Disaster Recovery it is important to evaluate whether these backups should be delivered without interruption during a DR event with workloads operating in AWS.
If this is a requirement for your DR solution then it will be necessary to ensure that the backup product is able to communicate with the instances in AWS and backups can be taken as they usually are. Depending on the backup product it may be possible to utilise AWS S3 (for example) as a media library for your enterprise backup solution; this may simplify your DR backup issue.
Support Model
What is your organisation’s support model for existing infrastructure (e.g. in-house or MSP)? Will this model be appropriate for support of the DR environment in AWS; will the same SLA’s be relevant or achievable when operating DR in AWS?
Ensure that these considerations are included in your BCP/DR plans and processes.
DR Operations
Successful execution of disaster recovery requires that appropriate planning and documentation is applied to the actual process of carrying out failover scenarios. Development, maintenance, and testing of recovery runsheets or processes is essential to ensure that when the crunch comes your recovery can be completed smoothly and with a minimum of fuss.
In addition, the processes that are developed need to be tested regularly to ensure that as your environment changes your plans are keeping up with those changes and continue to work.
Sandbox Environment
When developing a CloudEndure (or any) DR solution it will be important to be able to test solutions and develop processes to provide the optimal solution.
In order to be able to achieve this with minimal impact to existing environments (both production and non-production), it would be advisable to build a complete sandbox environment to allow testing and validation of your solutions to the items mentioned in this post. This sandbox may also be useful for the regular DR tests mentioned above.
Product Limitations
Source Operating System
CloudEndure supports a wide range of Operating System versions as detailed in the relevant sections of their documentation.
There are some particular limitations to note; RedHat/CentOS 6 and earlier, or Windows Server 2008 and earlier are not compatible with AWS Nitro based instances, such as C5 and M5 family, so these instance types should be avoided when configuring blueprints for recovery of servers running these older OS.
It is important to plan for these limitations, and solutions may require upgrade of existing on-premise servers which run unsupported operating systems. Launching instances in Test Mode, which CloudEndure supports without stopping replication, will allow you to validate that these issues have been avoided.
Multi-NIC Servers
It is quite common in on-premise environments to configure servers with multiple network interfaces (NICs). This may be for separation of application, and backup/monitoring traffic, or for increased network bandwidth through interface teaming.
CloudEndure will only launch AWS recovery instances with a single NIC, hence the configuration of network interfaces for AWS based workloads needs to be appropriately planned and implemented. If multiple interfaces are required in AWS it will be necessary to add secondary interfaces post-launch.
CloudEndure provides a post-launch scripting capability, whereby scripts can be developed and deployed to specific directories on the protected servers. These scripts are then executed after the AWS recovery instances are launched.
Conclusion
While it may not be as simple as having Business Continuity and IT Resilience a click away, with the necessary planning and design, and an appropriate AWS Target environment built to meet the organisation’s DR operational requirements, CloudEndure could be the answer to provision a DR capability for existing workloads at a lower cost.
The inclusion of AWS and CloudEndure in your solution can also unlock potential for automation of failover in some scenarios leveraging services such as AWS CloudWatch, AWS Lambda, and the CloudEndure API streamlining the recovery process.