Bring your own container(BYOC) with machine learning algorithm into AWS
Sinto Jose
This article explains how we can bring our own machine learning container to AWS. Amazon SageMaker helps machine learning specialists to prepare, build, train, and deploy high-quality machine learning models with high performance and scale. In SageMaker, the data scientists can package their own algorithms that can be trained and deployed in the SageMaker environment.
SageMakeralready supports the leading machine learning frameworks and mostly we don’t need to bring our container into SageMaker. Because the famous machine learning frameworks like Tensorflow/Apache-MXNet/Pytorch are already supported in sagemaker and you can simply supply the Python code that implements those algorithms. Below mentioned are some of the reasons for scientists to bring your own container.
In some cases scientists may need to customise some algorithms or if they want to try a complex model logic then the option is to bring your own container.
Algorithms release versions sometime frequently, but sometimes AWS updates the specific version later which may delay the scientist to experiment with the latest version.
Configure and install your dependencies and environment.
If you containerised the algorithm you can choose any training/hosting providers in AWS or Azure or GCP etc
Internally SageMaker makes use of Docker containers to allow users to train and deploy algorithms. Containers allow developers and data scientists to package software into standardized units that run consistently on any platform that supports Docker.
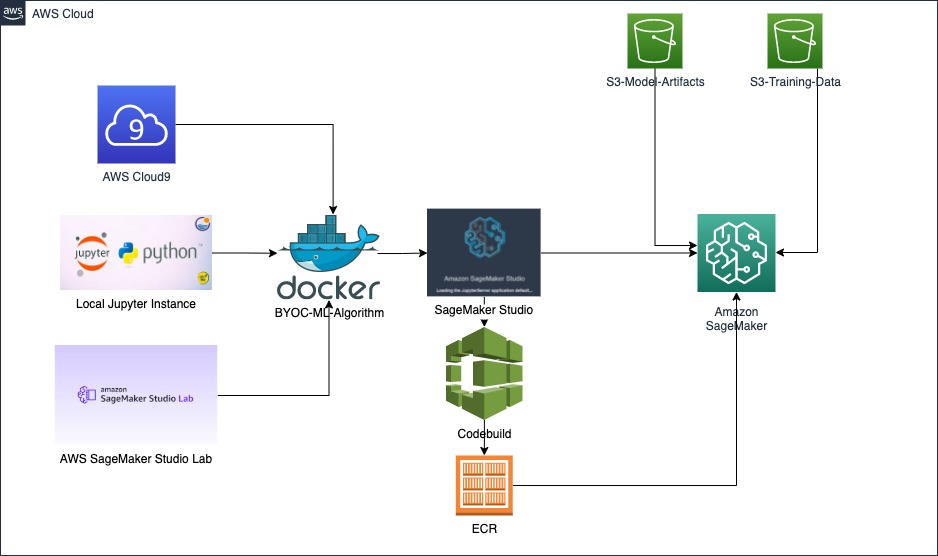
This is the architecture diagram of SageMaker using the container for training and deploying the ML model.
ML Algorithm
The algorithm used in this article Scikit learn Decision Tree Classifier and the example mentioned in the scikit website is used to demo here.
A decision tree is one of the supervised machine learning algorithms. This algorithm can be used for regression and classification problems but it is mostly used for classification problems. A decision tree follows a set of if-else conditions to visualize the data and classify it according to the conditions.
Sample code of a Scikit learn decision tree classifier.
from sklearn.treeimport DecisionTreeClassifier from sklearn importtree clf = tree.DecisionTreeClassifier(max_depth=3) clf.fit(X_train,y_train)
The example uses sklearn iris plant dataset and the objective of this problem is to classify iris flowers among three species (setosa, versicolor or virginica) from measurements of length and width of sepals and petals.
Development
Main files to consider for developing the BYOC container are
Dockerfile: Algorithm recipe of the container and package the complete frameworks and environment necessary for the ML algorithm to work.
train: Main program for training the model and you modify this code to bring your own training logic.
serve: program to start the inference server and listen for inference invocations.
predictor.py: inference prediction code needs to change based on the algorithm.
You can do the development initially using one of the below approaches.
Local development using Jupyter Notebook.
Amazon Sagemaker Studio Lab : Introduced in Dec 2021 as a preview mode. Its completely free tool and only registration required with email id. Good thing is that it supports both CPU and GPU. Tool is similar to Google Colab. This may take some days to get the approval for the access. For registration you can follow the link. https://studiolab.sagemaker.aws/
AWS Cloud9 Environment : In case if you don’t want to use the laptop for the dev then you can spin up a t2.small cloud9 instance. Good thing about cloud9 environment is that it is preinstalled with docker/aws cli/git etc. We can start the development right away.
I used the Cloud9 Environment approach and the repo contains an aws cloudformation script(byoc-cloud9-env.yaml) which creates an instance.
Once you logged into the Cloud9 environment, run the following commands to clone the repository and give the access.
cd ~/environment/ml-bring-your-own-container/container docker build -t sagemaker-decision-trees . cd ~/environment/ml-bring-your-own-container/container/local_test/ chmod +x *.sh
Generates the model artifacts as a pkl file decision-tree-model.pkl inside the model folder.
./train_local.sh sagemaker-decision-trees
Starts the server and listens for requests.
./serve_local.sh sagemaker-decision-trees
After that open another terminal for invoking the inference and the existing terminal can see the request coming through.
cd ~/environment/ml-bring-your-own-container/container/local_test/
./predict.sh payload.csv text/csv
API invocations can see in the listener server.
Once the algorithm looks fine after the development this can be pushed to ECR for later usage by executing the script build_and_push.sh.
If the data is large it is always better to train in aws. Later I will cover how to train and deploy the model using Amazon Sagemaker Studio.
IAM Permissions
The project requires IAM permissions to access the necessary AWS resources. The permission added here is the full access but in production use cases always follow the least privilege permission.
The IAM Role referenced in the GitHub repo has an iam-role.yaml file and it has all required permission to complete the project.
It contains one inline policy demo-decision-tree-policy and two AWS managed policy AmazonEC2ContainerRegistryFullAccess & AmazonSageMakerFullAccess. In addition to that, the role requires a trust relationship to be assumed by SageMaker and CodeBuild.
Amazon SageMaker Studio
Amazon SageMaker Studio provides a web-based visual interface where you can perform all ML development steps, improving data science team productivity. SageMaker Studio gives you complete access, control, and visibility into each step required to build, train, and deploy models. You can quickly upload data, create new notebooks, train and tune models, move back and forth between steps to adjust experiments, compare results, and deploy models.
Once you login to aws console go to Sagemaker. Under the SageMaker Domain select Studio.
This will prompt you for the IAM role and a user details and I am using the role which I created previously demo-decision-tree.
This will start the process of creating a domain for the studio to use with a user profile. After submitting, it will take some time to register the domain. Once the domain registration is completed you need to launch an app studio.
In your SageMaker Studio, on the left hand side, double click on the file scikit_bring_your_own.ipynb which prompts you to select an image which will be used in the kernel.
Running the cell one by one in the scikit_bring_your_own.ipynb file.
Install sagemaker-studio-image-build using pip to ensure you can use sm-docker to build the docker image.
sm-docker utility builds the docker image with the help of aws codebuild and will store it in the ECR.
Provide an s3 bucket prefix where we update the data.
After that, creates a Sagemaker session.
ML Training in AWS SageMaker
Invoking the fit in sagemaker which will generate model and store in s3. File name is model.tar.gz and inside contains the model pkl file.
ML Deployment in AWS SageMaker
During the deployment phase sagemaker creates a model inside the inference/endpoints which can be later used for seeing the inference result.
Inference prediction
Finally, predicting the result for the input test data using the sagemaker inference.
CleaningUp Resources
Run the cell to delete the endpoint.
Sagemaker Studio shutdown the apps and kernels.
Delete the Sagemaker Studio app, user and domain.
Delete the cloudformation stacks created using scripts iam-role.yaml and byoc-cloud9-env.yaml.
Summary
In conclusion, bringing your own container is the best option if data scientists need to bring a custom machine algorithm into AWS with the help of SageMaker and Docker. Once you have containerised the algorithm with the necessary frameworks and toolset, AWS makes it easy to train, deploy and predict the machine learning problem.