I’ve been using CloudFormation to describe my infrastructure and application architecture for over 5 years. Writing code is a craft that can take years to master (or at least have a learnt experience of what to do and what to avoid!). In this blog, I will share my tips on how to lay out your templates relative to your environment.
THE STACK
Imagine you have a simple WordPress application, https://myapp.com. It has a relational database, a set of EC2 instances in an autoscaling group running WordPress in PHP, and a load balancer in front. Your application sends some cloudwatch failures to an SNS topic for alarming and it also writes its logs to cloudwatch logs. Lastly you have an SSL certificate in ACM and a vanity DNS name that your end users use to access the website – ‘myapp.com’.
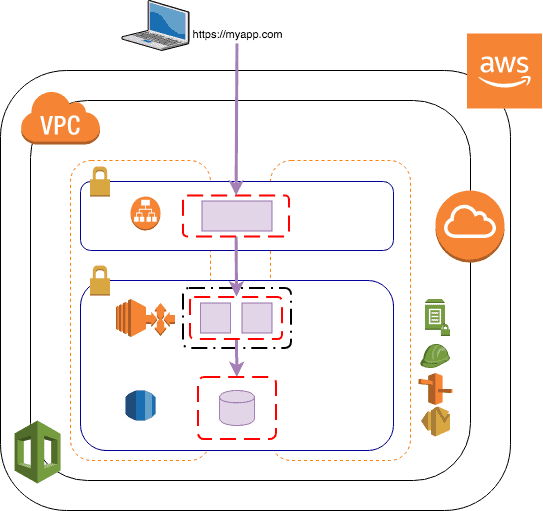
Now for a moment, let’s consider the underlying infrastructure of the account that you’re deploying the application into. Let’s assume you’ve also built a two layer VPC in multiple availability zones with appropriate routing.

TWO TIER V THREE TIER V N TIER
The number of layers within a tier is relative to the security posture of an organisation and the overarching topology of the infrastructure. Consider that patch management of EC2 instances that are deployed into private subnets. For simplicity of this blog, let’s assume a two tier VPC.
EXPOSING THE INTERFACE INTO THE CORE INFRASTRUCTURE
The application needs to know information about the core infrastructure. Specifically, the VpcId and the subnets to deploy into. There are really three ways to achieve this.

EXAMPLE: USING PARAMETER STORE
VPC STACK: SAVE PARAMETER
Resources :
...
VpcIdSave:
Type: "AWS::SSM::Parameter"
Properties:
Name: "/global/vpc01/vpcid"
Type: "String"
Value: !Ref Vpc
Description: "The VPC ID"
...
# Application stack: Use parameter store for VpcId
Parameters :
VpcId :
Type : 'AWS::SSM::Parameter::Value'
Default: ‘/global/vpc01/vpcid’
Note: The key to this model is to namespace your parameters in parameter store. For instance, include ‘/global’ or ‘/infrastructure’ to help differentiate core infrastructure with application, as you can set IAM policies on parameter wildcards. (Eg allow all of “/global/*” or deploy all of “/global/vpc02”). Additionally, also number your VPC for scenarios where you deploy multiple VPCs in the same region. Further, include this namespacing when you save your subnet ids – for instance /global/vpc01/subnet-puba.
EXAMPLE: USING EXPORTVALUE, IMPORTVALUE
# VPC Stack: save parameter
Outputs:
SubnetPubA:
Description: The ID of Pub A
Value: !Ref SubnetPubA
Export:
Name: !Sub "global::${AWS::StackName}::subnet-puba"
...
Note: this assumes the StackName is _‘vpc01’_
# Application stack: Use ImportValue for subnets
Resources:
ApplicationLoadBalancer:
Type: AWS::ElasticLoadBalancingV2::LoadBalancer
Properties:
Subnets:
- !ImportValue global::vpc01:subnet-puba
- !ImportValue global::vpc01:subnet-pubb
Note: Like parameter store, what is key with this model is to namespace export values for traceability. For instance, _include ‘global::’_ as a prefix.

My preference is to use ExportValue and if I cannot, to use parameter store. I find it useful to provide an interface of both ExportValue as well as a common named space parameter store keys for non-sensitive metadata to enable teams that deploy applications into the infrastructure to construct their template that they feel comfortable with.
Further, I find that if my application stack is specific for a business, and not a generic application being deployed out everywhere, the coupling costs using ImportValues are significantly less than the costs to manage parameters or mappings per environment.
LAYING OUT THE APPLICATION

When I first started writing CloudFormation, the fun part was building that application. I’d immediately pull up my editor and bash away until I was able to get that CREATE_COMPLETE. Now, prior to writing anything I take a step back and ask a few key questions:
- What is the lifecycle of each of the components of the CloudFormation stack? For instance, will I be regularly updating the LaunchConfiguration and rarely updating the security groups?
- What type of governance and security controls must be implemented?
- What are the deployment options does the application support?
- Who is responsible for the application, and if there is a mixed responsibility, how might I split things to codify each individual’s responsibility?
Finally, there two key principles that I must adhere to when writing CloudFormation:
- If I’m in a multi-account strategy (eg an account for ‘nonprod’ and one for ‘prod’) then I must be able to deploy the CloudFormation in all accounts and/or regions
- I must be able to stand up multiple copies of the same stack in the same VPC and account and/or regions.
WHAT ARE THE OPTIONS?
I generally see the following three options (or a combination therein):
- Option 1 is to write everything in that CloudFormation template.
- Option 2 is to split up the CloudFormation into pieces and connect them together via parameters, parameter store entries or ImportValues/ExportValues.
- Option 3 is not only splitting up the CloudFormation into components, but also splitting these components into different source control repositories.

OPTION 1
Having everything in a single template significantly simplifies your stack and it makes it really simple to create tight security between your components by using the ReturnValues of the resources that you create as references in IAM documents or security group rules. However there are some key things to consider: Do you want to couple your running RDS to the application version of your application?
OPTION 2
Splitting out the components of your application starts to make sense when you have a high change frequency for one part of your application and not the others. As a result, I find it better to lifecycle CloudFormation components relative to their change frequency. However when having multiple environments you need to consider how to connect them all together. Similar to how our application would find its infrastructure, I find that using ImportValues and ExportValues and Paramaster store key in connecting things together. This approach also enforces you to be explicit in the dependencies of your corresponding stacks to ensure their deployment order. Generally the ones at the bottom are the ones that change least frequently. If however you are finding that your core components need to change more regularly than the app, this approach is not the right approach for you.

OPTION 3
Similar to Option 2, Option 3 consists of splitting out the application stack however it also introduces a new dimension by saving items into different git repositories. This has some interesting side effects by allowing you to implement governance controls via a git Pull Request workflow. As an example, you can gate changes of IAM and Security Groups through Infosec, but bypass application infrastructure changes with this model.
MY PREFERENCE
My preference is either option (1) or option (2) as having CloudFormation templates commensurate to the lifecycle of the specific components minimises the blast radius when something is changed. I chose different git repos and different CI pipelines relative to any security or governance controls that need to be implemented. However there are a few key patterns that are subsequently required when choosing option (1) or (2) like environmental namespacing.
IMPLEMENT ENVIRONMENT NAMESPACING
When writing CloudFormation, I find myself introducing two key parameters that help me drive my stacks. Firstly I find myself adding “account” (for instance ‘prod’ or ‘nonprod’ assuming a multi account strategy) and secondly I almost always add something like “environment” (for instance “dev”, “int”, “qa”, “beta”, “prod” , “mine”, “yours”).
Using the pseudo parameters like "AWS::AccountId" and “AWS::Region” enables me to introduce logic relative to the specific account and location. For example “when deployed in the production account, ensure I am MultiAZ in my RDS”, or “when not in the production account, disable any cloudwatch alarms”.
CLOUDFORMATION STACK: EXAMPLE USING CONDITIONS
Parameters:
Account:
Description: The Target AWS Account Name
Type : 'AWS::SSM::Parameter::Value'
Default: "/global/account"
Environment:
Description: The Target Environment name
Default: “master”
Conditions:
IsProd: !Equals [ !Ref Account, “prod” ]
BranchBuild: !Not [ !Equals [ !Ref Environment, "master" ] ]
IsSydney: !Not [ !Equals [ !Ref AWS::Region, "ap-southeast-2" ] ]
Resources:
Foo:
Type: AWS::Foo
Condition: IsProd
.
Bar:
Type: AWS::Bar
Condition: BranchBuild
.
Mee:
Type: AWS::Mee
Condition: IsSydney
.
An “environment” parameter being passed in to all of the application stacks enables me to line up my resources using named resources or namespaced ExportValues/ Parameter Store entries for that specific environment so I can deployed another full set of stacks in the same account.
CLOUDFORMATION STACK: NAMESPACED EXPORT
Parameters:
Environment:
Type: String
Description: The Target Environment Name
Outputs:
LoadBalancer:
Description: The Load Balancer Logical Id
Value: !Ref LoadBalancer
Export:
Name: !Sub "environment::${Environment}::loadbalancer"
Occasionally I also include a third consistent parameter representing the version of the deployment – like a build number or git SHA. This can come in handy when producing a vanity DNS name for the load balancer.

WHAT ABOUT DNS?
Moving the management of the DNS record of ‘myapp.com’ outside of the application stack enables you to decouple the deployment from the release. I find myself having a simple DNS stack whose job is to generate an Alias record of my real application, eg https://myapp.com to the vanity name my application stack created. This facilitates Blue Green deployments which Amazon talk about in a lot of details here https://aws.amazon.com/quickstart/architecture/blue-green-deployment/
WHAT ABOUT SUBSTACKS?
An alternate approach to sticking CloudFormation created resources is to build out a single CloudFormation stack referencing substacks for each of those components. Instead of stitching together the RDS database to an EC2 instance via ImportValue, CloudFormation exports and parameters are instead. Substacks simply the first deployment of the application but in my opinion they begin to breakdown in that second deployment and/or whenever parts of the components need to be refactored. A future post will detail the pros and cons of using Stacksets against ImportValues.
KEY TAKEAWAYS:
- Consider the interfaces of the core infrastructure and ensure that these interfaces are consistent across all accounts in all regions that you plan on running infrastructure.
- Invest and adopt naming standards for those key interfaces be it in parameter store or ExportValue keys.
- Explore splitting your CloudFormation stacks commensurate to the lifecycle of the components in your application stack and adopt consistent environmental namespacing across all stacks.



