Change data capture (CDC) is a proven data integration pattern that has a wide range of applications. Among those, data replication to data lakes is a good use case in data engineering. Coupled with best-in-breed data lake formats such as Apache Hudi, we can build an efficient data replication solution. This is the first post of the data lake demo series. Over time, we’ll build a data lake that uses CDC. As a starting point, we’ll discuss the source database and CDC streaming infrastructure in the local environment.
Architecture
As described in a Red Hat IT topics article, change data capture (CDC) is a proven data integration pattern to track when and what changes occur in data then alert other systems and services that must respond to those changes. Change data capture helps maintain consistency and functionality across all systems that rely on data.
The primary use of CDC is to enable applications to respond almost immediately whenever data in databases change. Specifically its use cases cover microservices integration, data replication with up-to-date data, building time-sensitive analytics dashboards, auditing and compliance, cache invalidation, full-text search and so on. There are a number of approaches for CDC – polling, dual writes and log-based CDC. Among those, log-based CDC has advantages to other approaches.
Both Amazon DMS and Debezium implement log-based CDC. While the former is a managed service, the latter can be deployed to a Kafka cluster as a (source) connector. It uses Apache Kafka as a messaging service to deliver database change notifications to the applicable systems and applications. Note that Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems by connectors. In AWS, we can use Amazon MSK and MSK Connect for building a Debezium based CDC solution.
Data replication to data lakes using CDC can be much more effective if data is stored to a format that supports atomic transactions and consistent updates. Popular choices are Apache Hudi, Apache Iceberg and Delta Lake. Among those, Apache Hudi can be a good option as it is well-integrated with AWS services.
Below shows the architecture of the data lake solution that we will be building in this series of posts.
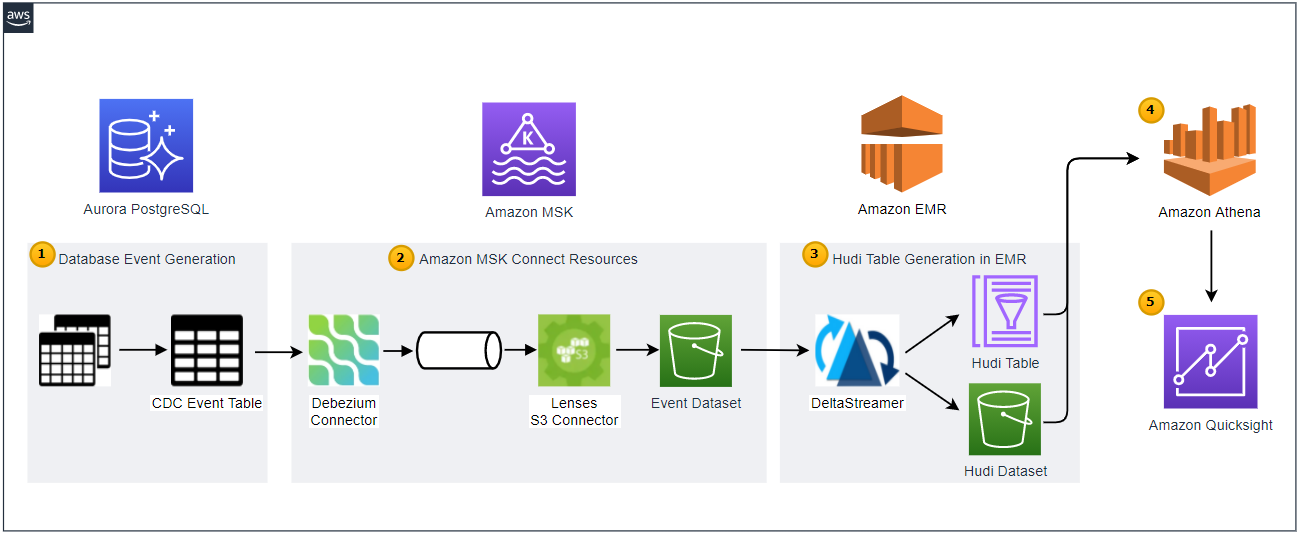
Employing the transactional outbox pattern, the source database publishes change event records to the CDC event table. The event records are generated by triggers that listen to insert and update events on source tables.
CDC is implemented in a streaming environment and Amazon MSK is used to build the streaming infrastructure. In order to process the real-time CDC event records, a source and sink connectors are set up in Amazon MSK Connect. The Debezium connector for PostgreSQL is used as the source connector and the Lenses S3 connector is used as the sink connector. The sink connector pushes messages to a S3 bucket.
Hudi DeltaStreamer is run on Amazon EMR. As a spark application, it reads files from the S3 bucket and upserts Hudi records to another S3 bucket. The Hudi table is created in the AWS Glue Data Catalog.
The Hudi table is queried in Amazon Athena while the table is registered in the AWS Glue Data Catalog.
Dashboards are created in Amazon Quicksight where the dataset is created using Amazon Athena.
As a starting point, we’ll discuss the source database and streaming infrastructure in the local environment.
Source Database
Data Model
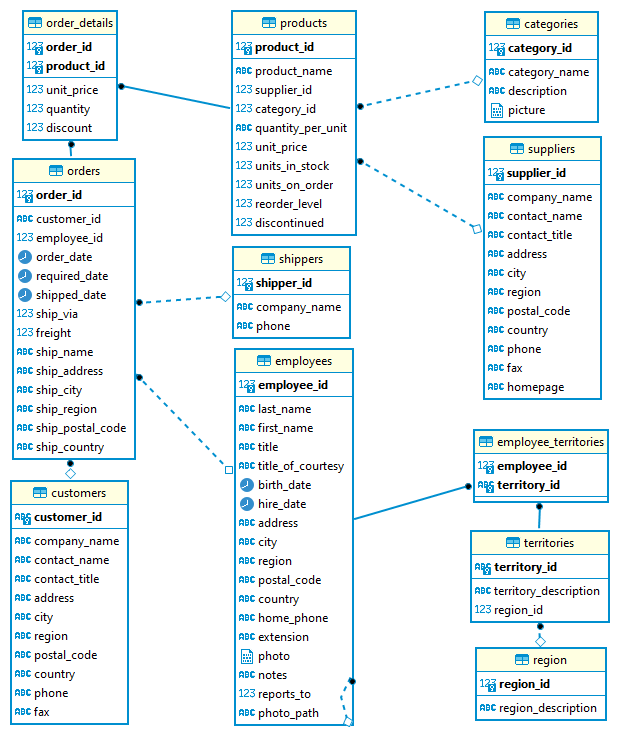
We will use the Northwind database as the source database. It was originally created by Microsoft and used by various tutorials of their database products. It contains the sales data for a fictitious company called Northwind Traders that deals with specialty foods from around the world. As shown in the following entity relationship diagram, it includes a schema for a small business ERP with customers, products, orders, employees and so on. The version that is ported to PostgreSQL is obtained from YugabyteDB sample datasets and the SQL scripts can be found in the project GitHub repository. For local development, a service is created using docker compose and it’ll be illustrated in the next section.
Outbox Table and Event Generation
It is straightforward to capture changes from multiple tables in a database using Kafka connectors where a separate topic is created for each table. Data ingestion to Hudi, however, can be complicated if messages are stored in multiple Kafka topics. Note that we will use the DeltaStreamer utility and it maps to a single topic. In order to simplify the data ingestion process, we can employ the transactional outbox pattern. Using this pattern, we can create an outbox table (cdc_events) and upsert a record to it when a new transaction is made. In this way, all database changes can be pushed to a single topic, resulting in one DeltaStreamer process to listen to the change events.
Below shows the table creation statement of the outbox table. It aims to store all details of an order entry in a row. The columns that have the JSONB data type store attributes of other entities. For example, the order_items column includes ordered product information. As multiple products can be purchased, it keeps an array of product id, unit price, quantity and discount.
— ./data/sql/03_cdc_events.sql CREATE TABLE cdc_events( |
In order to create event records, triggers are added to the orders and order_details tables. They execute the fn_insert_order_event function after an INSERT or UPDATE action occurs to the respective tables. Note the DELETE action is not considered in the event generation process for simplicity. The trigger function basically collects details of an order entry and attempts to insert a new record to the outbox table. If a record with the same order id exists, it updates the record instead.
— ./data/sql/03_cdc_events.sql CREATE TRIGGER orders_triggered
CREATE OR REPLACE FUNCTION fn_insert_order_event() $$; |
Create Initial Event Records
In order to create event records for existing order entries, a stored procedure is created – usp_init_order_events. It is quite similar to the trigger function and can be checked in the project repository. The procedure is called at database initialization and a total of 829 event records are created by that.
— ./data/sql/03_cdc_events.sql |
Below shows a simplified event record, converted into JSON. For the order with id 10248, 3 products are ordered by a customer whose id is VINET.
{ |
Create Publication
As discussed further in the next section, we’ll be using the native pgoutput logical replication stream support. Debezium, Kafka source connector, automatically creates a publication that contains all tables if it doesn’t exist. It can cause trouble to update a record to a table that doesn’t have the primary key or replica identity. So as to handle such an issue, a publication that contains only the outbox table is created. This publication will be used when configuring the source connector.
— ./data/sql/03_cdc_events.sql |
CDC Development
Docker Compose
The Confluent platform can be handy for local development although we’ll be deploying the solution using Amazon MSK and MSK Connect. The quick start guide provides a docker compose file that includes its various components in separate services. It also contains the control center, a graphical user interface, which helps check brokers, topics, messages and connectors easily.
Additionally we need a PostgreSQL instance for the Northwind database and a service named postgres is added. The database is initialised by a set of SQL scripts. They are executed by volume-mapping to the initialisation folder – the scripts can be found in the project repository. Also the Kafka Connect instance, running in the connect service, needs an update to include the source and sink connectors. It’ll be illustrated further below.
Below shows a cut-down version of the docker compose file that we use for local development. The complete file can be found in the project repository.
# ./docker-compose.yml version: “2” CONNECT_PLUGIN_PATH: “/usr/share/java,/usr/share/confluent-hub-components,/usr/local/share/kafka/plugins” |
Install Connectors
We use the Debezium connector for PostgreSQL as the source connector and Lenses S3 Connector as the sink connector. The source connector is installed via the confluent hub client while the sink connector is added as a community connector. Note that the environment variable of CONNECT_PLUGIN_PATH is updated to include the kafka plugin folder (/usr/local/share/kafka/plugins).
# .connector/local/cp-server-connect-datagen/Dockerfile FROM cnfldemos/cp-server-connect-datagen:0.5.0–6.2.1 |
Start Services
After starting the docker compose services, we can check a local Kafka cluster in the control center via http://localhost:9021. We can go to the cluster overview page by clicking the cluster card item.
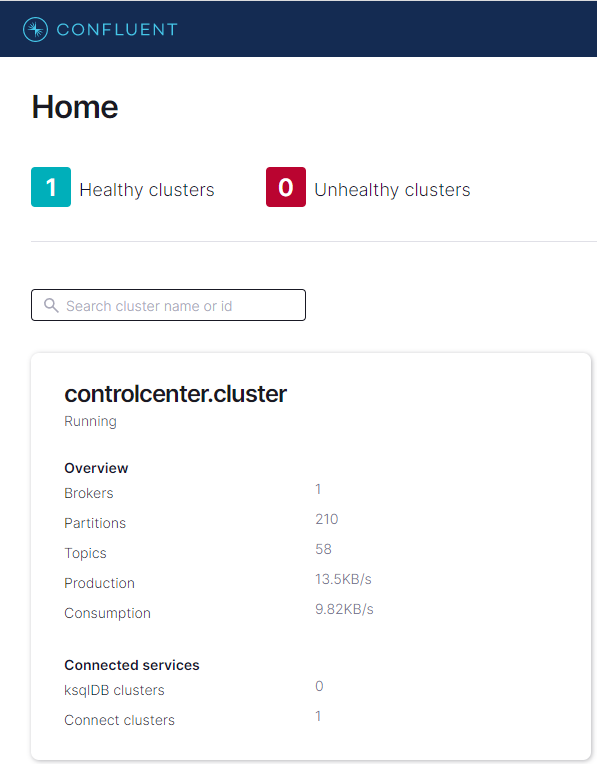
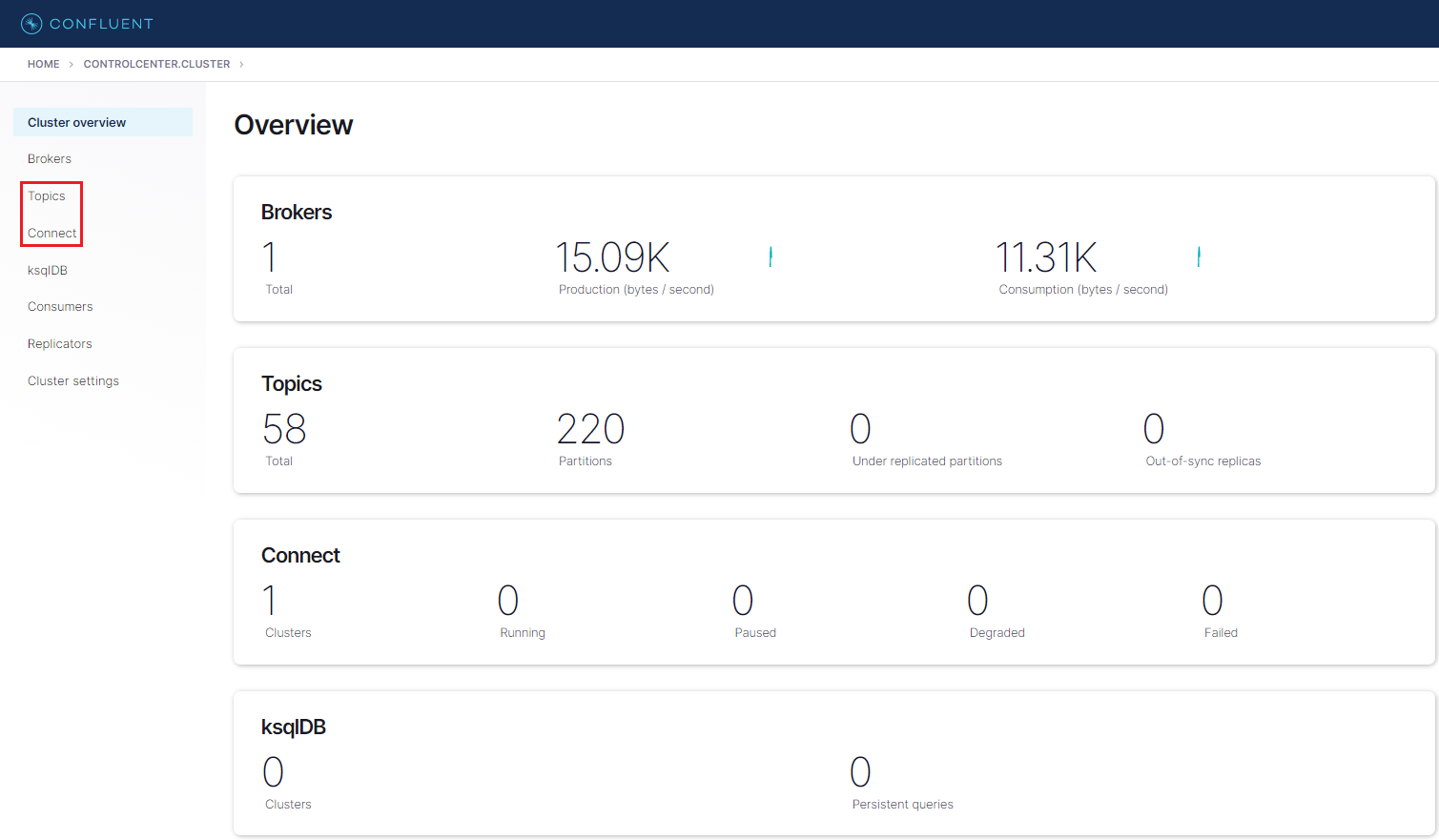
We can check an overview of the cluster in the page. For example, it shows the cluster has 1 broker and there is no running connector. On the left side, there are menus for individual components. Among those, Topics and Connect will be our main interest in this post.
Create Connectors
Source Connector
“Debezium’s PostgreSQL connector captures row-level changes in the schemas of a PostgreSQL database. PostgreSQL versions 9.6, 10, 11, 12 and 13 are supported. The first time it connects to a PostgreSQL server or cluster, the connector takes a consistent snapshot of all schemas. After that snapshot is complete, the connector continuously captures row-level changes that insert, update, and delete database content and that were committed to a PostgreSQL database. The connector generates data change event records and streams them to Kafka topics. For each table, the default behavior is that the connector streams all generated events to a separate Kafka topic for that table. Applications and services consume data change event records from that topic.”
The connector has a number of connector properties including name, connector class, database connection details, key/value converter and so on – the full list of properties can be found in this page. The properties that need explanation are listed below.
plugin.name – Using the logical decoding feature, an output plug-in enables clients to consume changes to the transaction log in a user-friendly manner. Debezium supports decoderbufs, wal2json and pgoutput plug-ins. Both wal2json and pgoutput are available in Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. decoderbufs requires a separate installation and it is excluded from the option. Among the 2 supported plug-ins, pgoutput is selected because it is the standard logical decoding output plug-in in PostgreSQL 10+ and has better performance for large transactions.
publication.name – With the pgoutput plug-in, the Debezium connector creates a publication (if not exists) and sets publication.autocreate.mode to all_tables. It can cause an issue to update a record to a table that doesn’t have the primary key or replica identity. We can set the value to filtered where the connector adjusts the applicable tables by other property values. Alternatively we can create a publication on our own and add the name to publication.name property. I find creating a publication explicitly is easier to maintain. Note a publication alone is not sufficient to handle the issue. All affected tables by the publication should have the primary key or replica identity. In our example, the orders and order_details tables should meet the condition. In short, creating an explicit publication can prevent the event generation process from interrupting other processes by limiting the scope of CDC event generation.
key.converter/value.converter – Although Avro serialization is recommended, JSON is a format that can be generated without schema registry and can be read by DeltaStreamer.
transforms* – A Debezium event data has a complex structure that provides a wealth of information. It can be quite difficult to process such a structure using DeltaStreamer. Debezium’s event flattening single message transformation (SMT) is configured to flatten the output payload.
Note once the connector is deployed, the CDC event records will be published to demo.datalake.cdc_events topic.
// ./connector/local/source-debezium.json { |
The source connector is created using the API and its status can be checked as shown below.
## create debezium source connector |
Sink Connector
“Lenses S3 Connector is a Kafka Connect sink connector for writing records from Kafka to AWS S3 Buckets. It extends the standard connect config adding a parameter for a SQL command (Lenses Kafka Connect Query Language or “KCQL”). This defines how to map data from the source (in this case Kafka) to the target (S3). Importantly, it also includes how data should be partitioned into S3, the bucket names and the serialization format (support includes JSON, Avro, Parquet, Text, CSV and binary).”
I find the Lenses S3 connector is more straightforward to configure than the Confluent S3 sink connector for its SQL-like syntax. The KCQL configuration indicates that object files are set to be
moved from a Kafka topic (demo.datalake.cdc_events) to an S3 bucket (data-lake-demo-cevo) with object prefix of cdc-events-local,
partitioned by customer_id and order_id eg) customer_id=<customer-id>/order_id=<order-id>,
stored as the JSON format and,
flushed every 60 seconds or when there are 50 records.
// ./connector/local/sink-s3.json { |
The sink connector is created using the API and its status can be checked as shown below.
## create s3 sink connector |
We can also check the details of the connectors from the control center.

In the Topics menu, we are able to see that the demo.datalake.cdc_events topic is created by the Debezium connector.
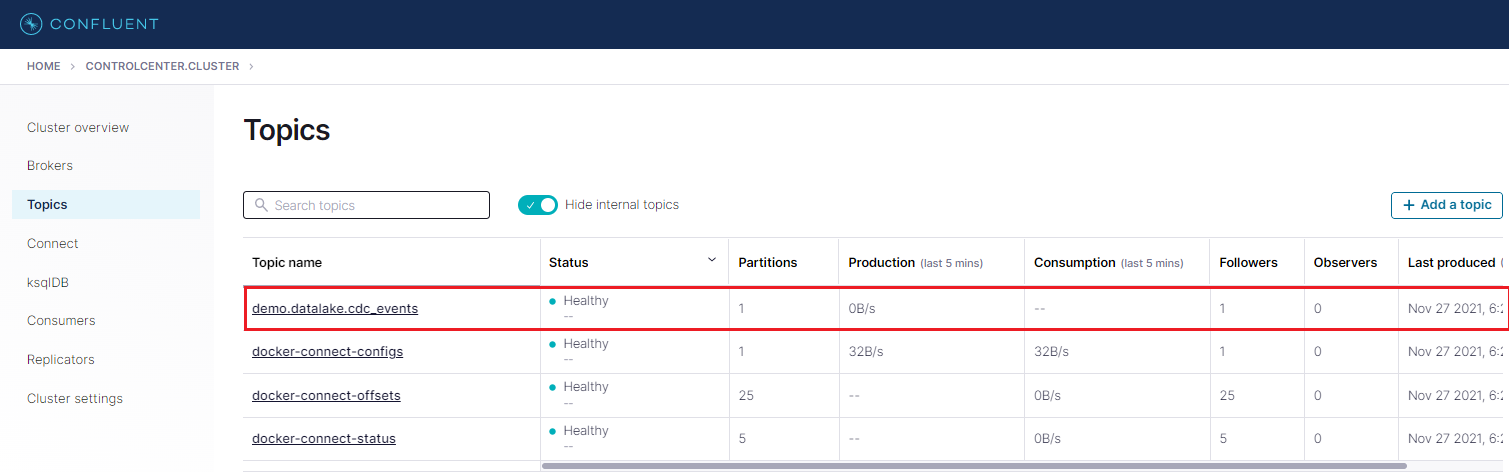
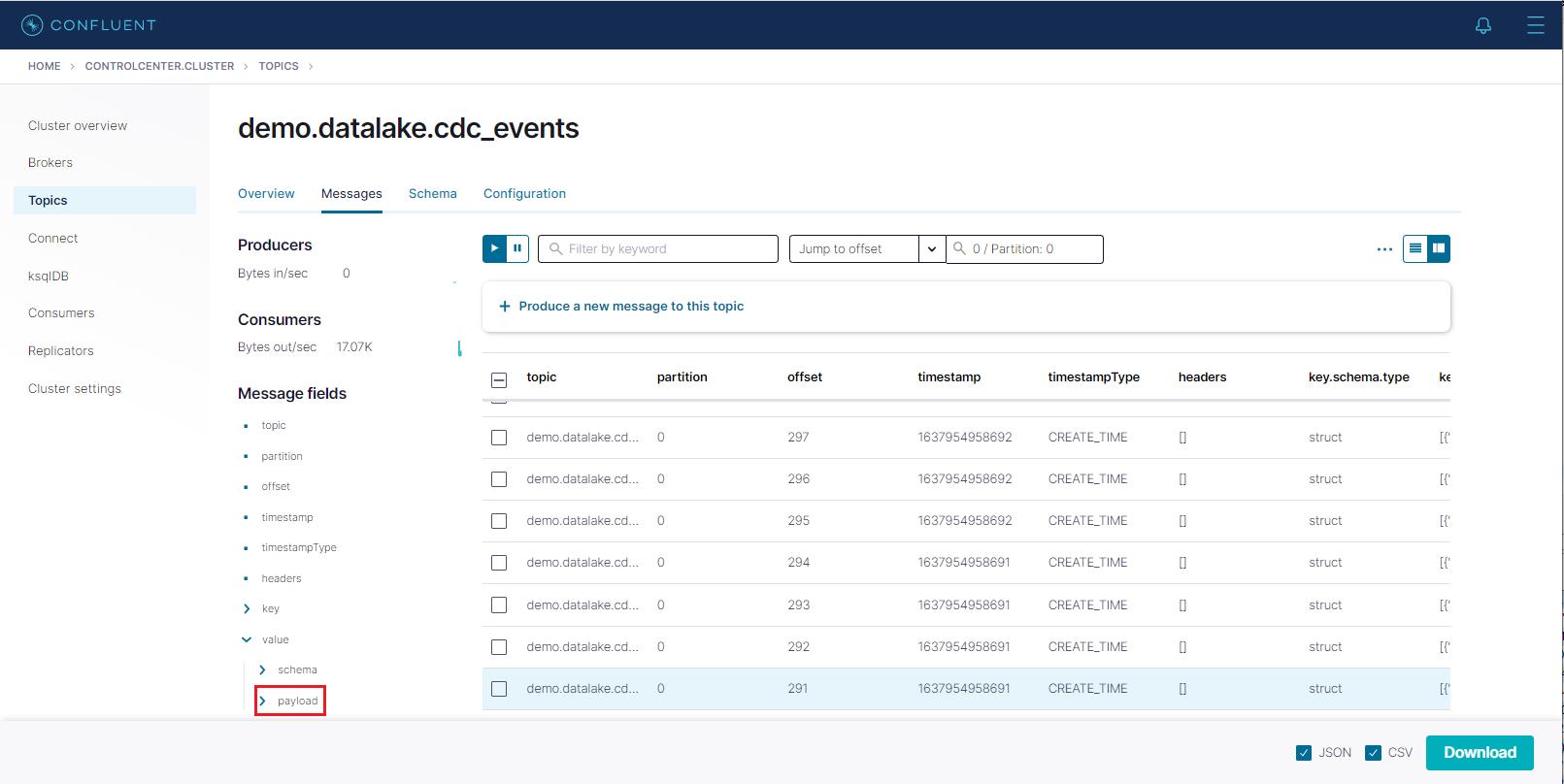
We can check messages of a topic by clicking the topic name. After adding an offset value (eg 0) to the input element, we are able to see messages of the topic. We can check message fields on the left hand side or download a message in the JSON or CSV format.
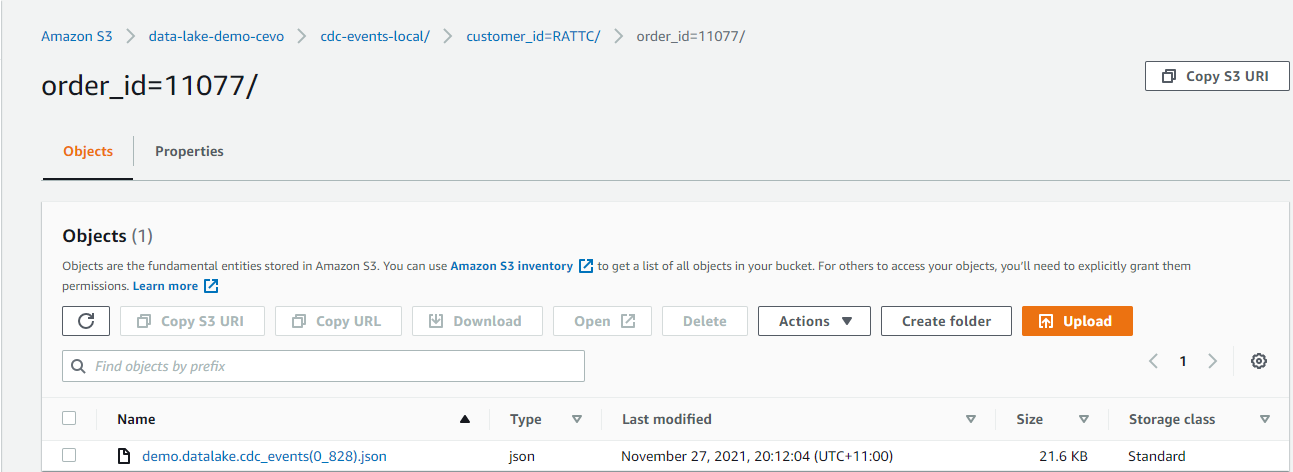
Check Event Output Files
We can check the output files that are processed by the sink connector in S3. Below shows an example record where customer_id is RATTC and order_id is 11077. As configured, the objects are prefixed by cdc-events-local and further partitioned by customer_id and order_id. The naming convention of output files is <topic-name>(partition_offset).ext.
Update Event Example
The above order record has a NULL shpped_date value. When we update it using the following SQL statement, we should be able to see a new output file with the updated value.
BEGIN TRANSACTION; |
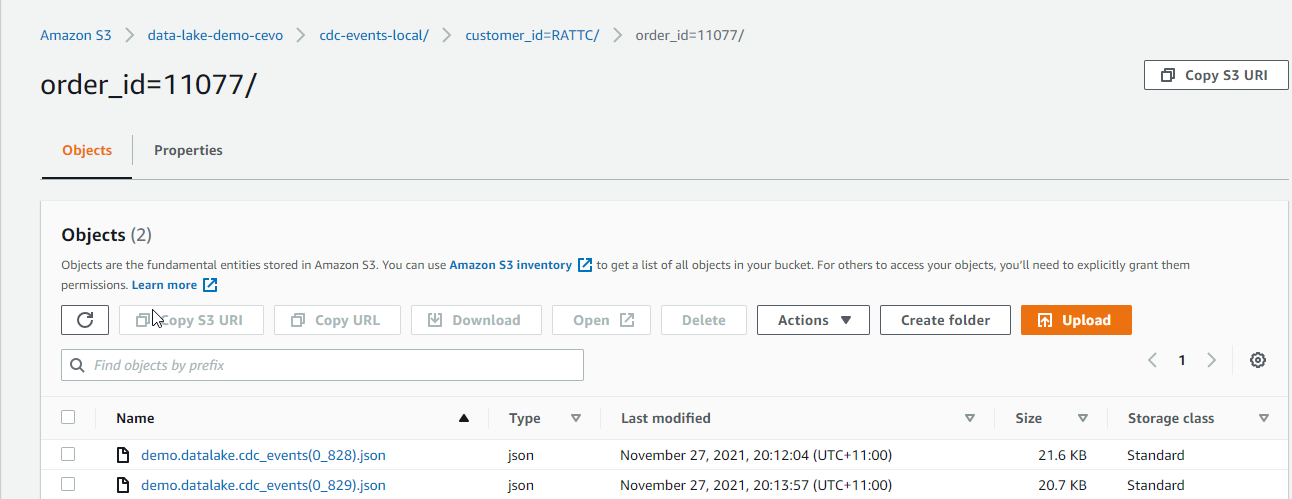
In S3, we are able to see that a new output file is stored. In the new output file, the shipped_date value is updated to 10392. Note that the Debezium connector converts the DATE type to the INT32 type, which represents the number of days since the epoch.
Insert Event Example
When a new order is created, it’ll insert a record to the orders table as well as one or more order items to the order_details table. Therefore we expect multiple event records will be created when a new order is created. We can check it by inserting an order and related order details items.
|
BEGIN TRANSACTION; |
We can see the output file includes 4 JSON objects where the first object has NULL order_items and products value. We can also see that those values are expanded gradually in subsequent event records.

Conclusion
We discussed a data lake solution where data ingestion is performed using change data capture (CDC) and the output files are upserted to a Hudi table. Being registered to Glue Data Catalog, it can be used for ad-hoc queries and report/dashboard creation. The Northwind database is used as the source database and, following the transactional outbox pattern, order-related changes are upserted to an outbox table by triggers. The data ingestion is developed using Kafka connectors in the local Confluent platform where the Debezium for PostgreSQL is used as the source connector and the Lenses S3 sink connector is used as the sink connector. We confirmed the order creation and update events are captured as expected and it is ready for production deployment. In the next post, we’ll build the data ingestion part of the solution with Amazon MSK and MSK Connect.



