In the previous post, we discussed a data lake solution where data ingestion is performed using change data capture (CDC) and the output files are upserted to an Apache Hudi table. Being registered to Glue Data Catalog, it can be used for ad-hoc queries and report/dashboard creation. The Northwind database is used as the source database and, following the transactional outbox pattern, order-related changes are upserted to an outbox table by triggers. The data ingestion is developed using Kafka connectors in the local Confluent platform where the Debezium for PostgreSQL is used as the source connector and the Lenses S3 sink connector is used as the sink connector. We confirmed the order creation and update events are captured as expected and it is ready for production deployment. In this post, we’ll build the CDC part of the solution on AWS using Amazon MSK and MSK Connect.
Architecture
As described in a Red Hat IT topics article, change data capture (CDC) is a proven data integration pattern to track when and what changes occur in data then alert other systems and services that must respond to those changes. Change data capture helps maintain consistency and functionality across all systems that rely on data.
The primary use of CDC is to enable applications to respond almost immediately whenever data in databases change. Specifically its use cases cover microservices integration, data replication with up-to-date data, building time-sensitive analytics dashboards, auditing and compliance, cache invalidation, full-text search and so on. There are a number of approaches for CDC – polling, dual writes and log-based CDC. Among those, log-based CDC has advantages to other approaches.
Both Amazon DMS and Debezium implement log-based CDC. While the former is a managed service, the latter can be deployed to a Kafka cluster as a (source) connector. It uses Apache Kafka as a messaging service to deliver database change notifications to the applicable systems and applications. Note that Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems by connectors. In AWS, we can use Amazon MSK and MSK Connect for building a Debezium based CDC solution.
Data replication to data lakes using CDC can be much more effective if data is stored to a format that supports atomic transactions and consistent updates. Popular choices are Apache Hudi, Apache Iceberg and Delta Lake. Among those, Apache Hudi can be a good option as it is well-integrated with AWS services.
Below shows the architecture of the data lake solution that we will be building in this series of posts.

Employing the transactional outbox pattern, the source database publishes change event records to the CDC event table. The event records are generated by triggers that listen to insert and update events on source tables. See the Source Database section of the previous post for details.
CDC is implemented in a streaming environment and Amazon MSK is used to build the streaming infrastructure. In order to process the real-time CDC event records, a source and sink connectors are set up in Amazon MSK Connect. The Debezium connector for PostgreSQL is used as the source connector and the Lenses S3 connector is used as the sink connector. The sink connector pushes messages to a S3 bucket.
Hudi DeltaStreamer is run on Amazon EMR. As a spark application, it reads files from the S3 bucket and upserts Hudi records to another S3 bucket. The Hudi table is created in the AWS Glue Data Catalog.
The Hudi table is queried in Amazon Athena while the table is registered in the AWS Glue Data Catalog.
Dashboards are created in Amazon Quicksight where the dataset is created using Amazon Athena.
In this post, we’ll build the CDC part of the solution on AWS using Amazon MSK and MSK Connect.
Infrastructure
VPC
We’ll build the data lake solution in a dedicated VPC. The VPC is created in the Sydney region and it has private and public subnets in 2 availability zones. Note the source database, MSK cluster/connectors and EMR cluster will be deployed to the private subnets. The CloudFormation template can be found in the Free Templates for AWS CloudFormation– see the VPC section for details..
NAT Instances
NAT instances are created in each of the availability zone to forward outbound traffic to the internet. The CloudFormation template can be found in the VPC section of the site as well.
VPN Bastion Host
We can use a VPN bastion host to access resources in the private subnets. The free template site provides both SSH and VPN bastion host templates and I find the latter is more convenient. It can be used to access other resources via different ports as well as be used as a SSh bastion host. The CloudFormation template creates an EC2 instance in one of the public subnets and installs a SoftEther VPN server. The template requires you to add the pre-shared key and the VPN admin password, which can be used to manage the server and create connection settings for the VPN server. After creating the CloudFormation stack, we need to download the server manager from the download page and to install the admin tools.
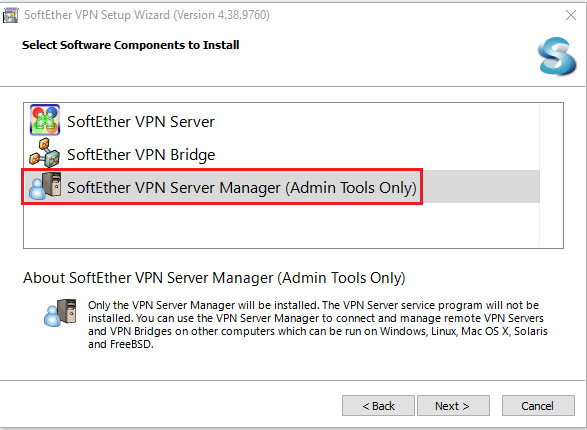
After that, we can create connection settings for the VPN server by providing the necessary details as marked in red boxes below. We should add the public IP address of the EC2 instance and the VPN admin password.
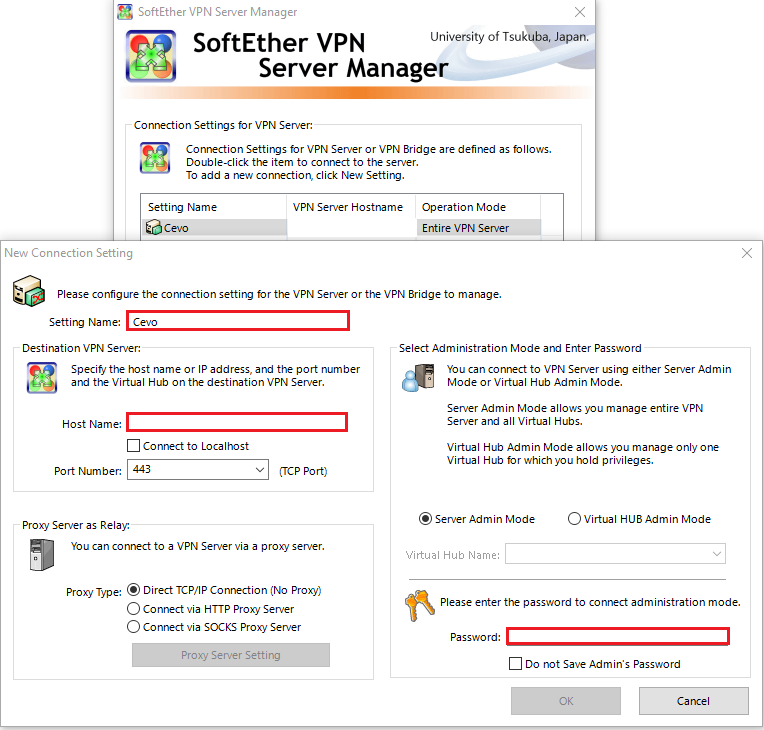
The template also has VPN username and password parameters and those are used to create a user account in the VPN bastion server. Using the credentials we can set up a VPN connection using the SoftEther VPN client program – it can be downloaded on the same download page. We should add the public IP address of the EC2 instance to the host name and select DEFAULT as the virtual hub name.
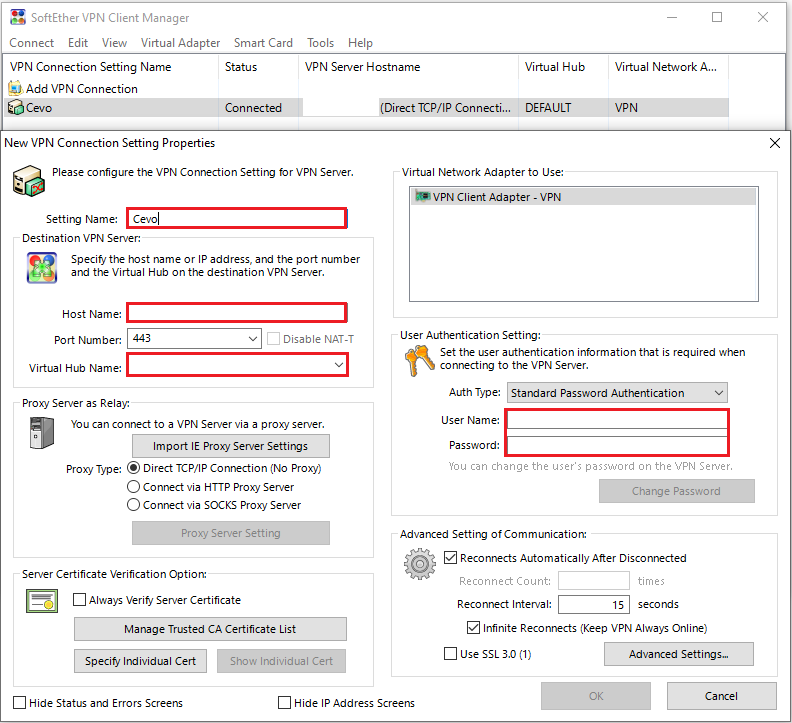
After that, we can connect to the VPN bastion host and access resources in the private subnets.
Aurora PostgreSQL
We create the source database with Aurora PostgreSQL. The CloudFormation template from the free template site creates database instances in multiple availability zones. We can simplify it by creating only a single instance. Also, as we’re going to use the pgoutput plugin for the Debezium source connector, we need to set rds.logical_replication value to “1” in the database cluster parameter group. Note to add the CloudFormation stack name of the VPN bastion host to the ParentSSHBastionStack parameter value so that the database can be accessed by the VPN bastion host. Also note that the template doesn’t include an inbound rule from the MSK cluster that’ll be created below. For now, we need to add the inbound rule manually. The updated template can be found in the project GitHub repository.
Source Database
As with the local development, we can create the source database by executing the db creation SQL scripts. A function is created in Python. After creating the datalake schema and setting the search path of the database (devdb) to it, it executes the SQL scripts.
# ./data/load/src.py def create_northwind_db(): |
In order to facilitate the db creation, a simple command line application is created using the Typer library.
# ./data/load/main.py import typer |
It has a set of options to specify – database host, post, database name and username. The database password is set to be prompted and an additional confirmation is required. If all options are provided, the app runs and creates the source database.
(venv) jaehyeon@cevo:~/data-lake-demo$ python data/load/main.py –help |
As illustrated in the previous post, it inserts 829 order event records to the cdc_events table.
MSK Cluster
We’ll create a MSK cluster with 2 brokers (servers). The instance type of brokers is set to kafka.m5.large. Note that the smallest instance type of kafka.t3.small may look better for development but we’ll have a failed authentication error when IAM Authentication is used for access control and connectors are created on MSK Connect. It is because the T3 instance type is limited to 1 TCP connection per broker per second and if the frequency is higher than the limit, that error is thrown. Note, while it’s possible to avoid it by updating reconnect.backoff.ms to 1000, it is not allowed on MSK Connect.
When it comes to inbound rules of the cluster security group, we need to configure that all inbound traffic is allowed from its own security group. This is because connectors on MSK Connect are deployed with the same security group of the MSK cluster and they should have access to it. Also we need to allow port 9098 from the security group of the VPN bastion host – 9098 is the port for establishing the initial connection to the cluster when IAM Authentication is used.
Finally a cluster configuration is created manually as it’s not supported by CloudFormation and its ARN and revision number are added as parameters. The configuration is shown below.
auto.create.topics.enable = true |
The CloudFormation template can be found in the project GitHub repository.
MSK Connect Role
As we use IAM Authentication for access control, the connectors need to have permission on the cluster, topic and group. Also the sink connector should have access to put output files to the S3 bucket. For simplicity, a single connector role is created for both source and sink connectors in the same template.
CDC Development
In order to create a connector on MSK Connect, we need to create a custom plugin and the connector itself. A custom plugin is a set of JAR files containing the implementation of one or more connectors, transforms, or converters and installed on the workers of the connect cluster where the connector is running. Both the resources are not supported by CloudFormation and can be created on AWS Console or using AWS SDK.
Custom Plugins
We need plugins for the Debezium source and S3 sink connectors. Plugin objects can be saved to S3 in either JAR or ZIP file format. We can download them from the relevant release/download pages of Debezium and Lenses Stream Reactor. Note to put contents at the root level of the zip archives. Once they are saved to S3, we can create them simply by specifying their S3 URIs.
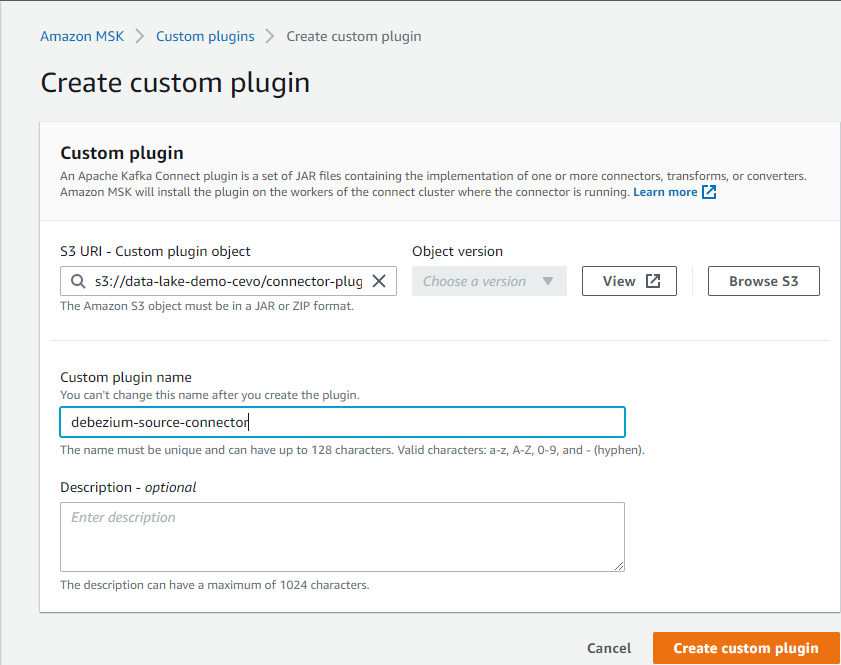
MSK Connectors
Source Connector
“Debezium’s PostgreSQL connector captures row-level changes in the schemas of a PostgreSQL database. PostgreSQL versions 9.6, 10, 11, 12 and 13 are supported. The first time it connects to a PostgreSQL server or cluster, the connector takes a consistent snapshot of all schemas. After that snapshot is complete, the connector continuously captures row-level changes that insert, update, and delete database content and that were committed to a PostgreSQL database. The connector generates data change event records and streams them to Kafka topics. For each table, the default behavior is that the connector streams all generated events to a separate Kafka topic for that table. Applications and services consume data change event records from that topic.”
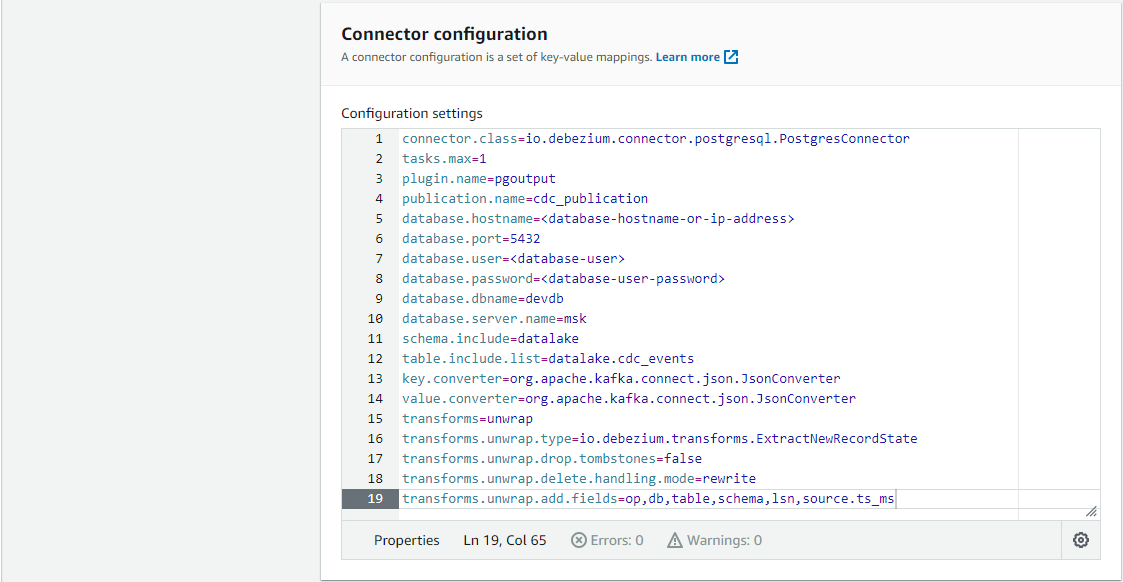
The connector has a number of connector properties including name, connector class, database connection details, key/value converter and so on – the full list of properties can be found in this page. The properties that need explanation are listed below.
plugin.name – Using the logical decoding feature, an output plug-in enables clients to consume changes to the transaction log in a user-friendly manner. Debezium supports decoderbufs, wal2json and pgoutput plug-ins. Both wal2json and pgoutput are available in Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. decoderbufs requires a separate installation and it is excluded from the option. Among the 2 supported plug-ins, pgoutput is selected because it is the standard logical decoding output plug-in in PostgreSQL 10+ and has better performance for large transactions.
publication.name – With the pgoutput plug-in, the Debezium connector creates a publication (if not exists) and sets publication.autocreate.mode to all_tables. It can cause an issue to update a record to a table that doesn’t have the primary key or replica identity. We can set the value to filtered where the connector adjusts the applicable tables by other property values. Alternatively we can create a publication on our own and add the name to publication.name property. I find creating a publication explicitly is easier to maintain. Note a publication alone is not sufficient to handle the issue. All affected tables by the publication should have the primary key or replica identity. In our example, the orders and order_details tables should meet the condition. In short, creating an explicit publication can prevent the event generation process from interrupting other processes by limiting the scope of CDC event generation.
key.converter/value.converter – Although Avro serialization is recommended, JSON is a format that can be generated without schema registry and can be read by DeltaStreamer.
transforms* – A Debezium event data has a complex structure that provides a wealth of information. It can be quite difficult to process such a structure using DeltaStreamer. Debezium’s event flattening single message transformation (SMT) is configured to flatten the output payload.
Note once the connector is deployed, the CDC event records will be published to msk.datalake.cdc_events topic.
# ./connector/msk/source-debezium.properties |
The connector can be created in multiple steps. The first step is to select the relevant custom plugin from the custom plugins list.
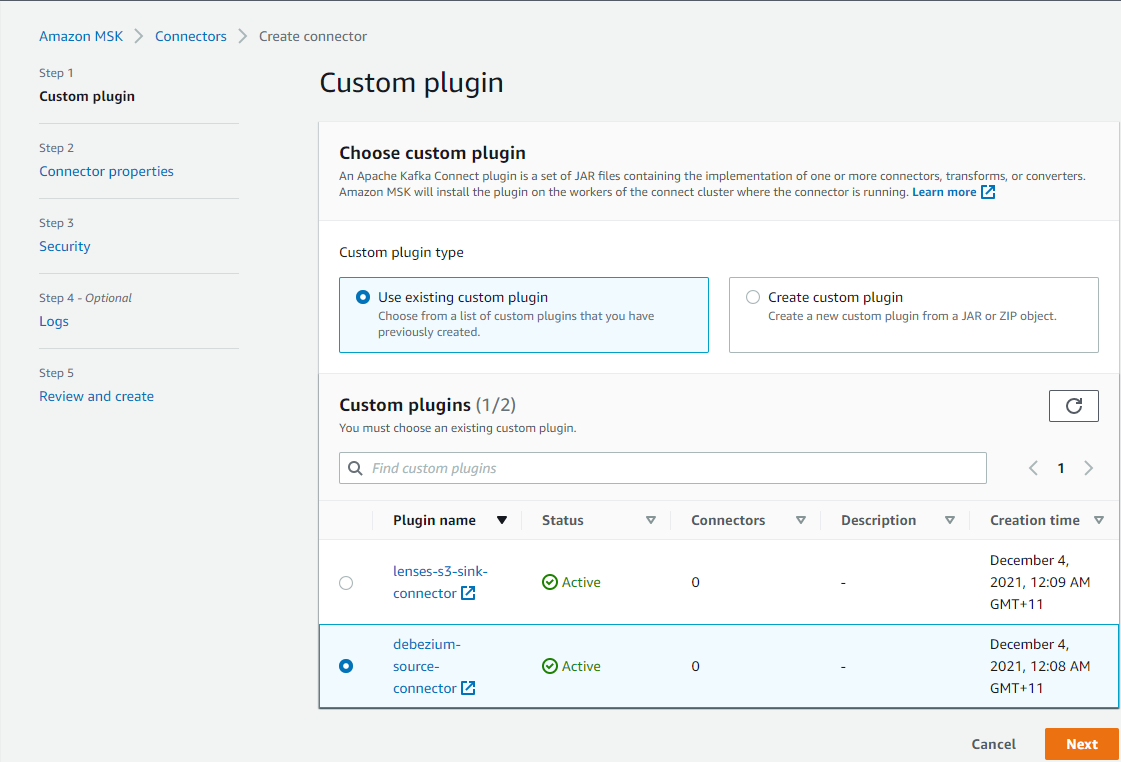
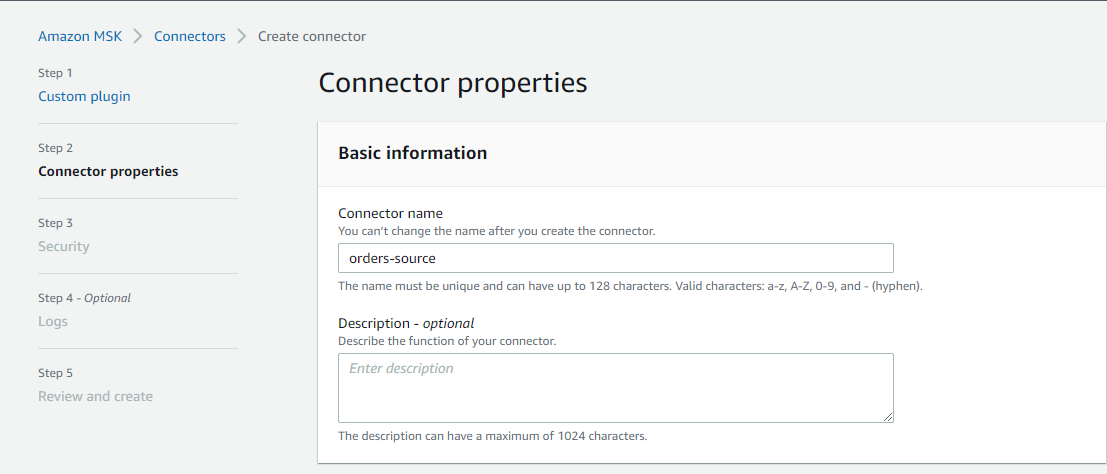
In the second step, we can configure connector properties. Applicable properties are
-
Connector name and description
-
Apache Kafka cluster (MSK or self-managed) with an authentication method
-
Connector configuration
-
Connector capacity – Autoscaled or Provisioned
-
Worker configuration
-
IAM role of the connector
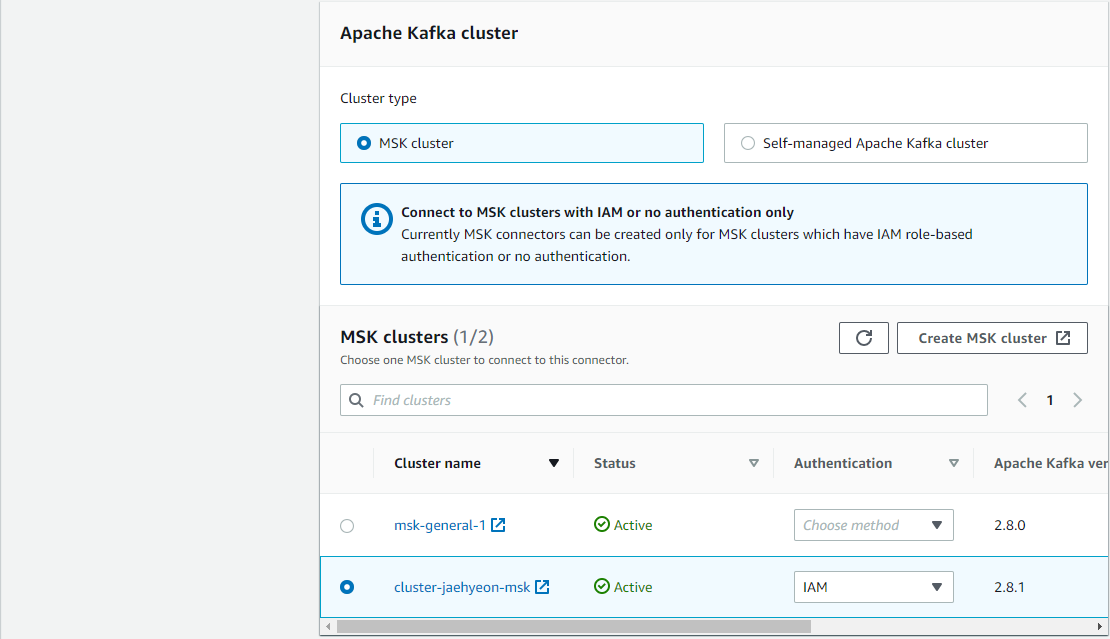
In the third step, we configure cluster security. As we selected IAM Authentication, only TLS encryption is available.

Finally we can configure logging. A log group is created in the CloudFormation and we can add its ARN.
After reviewing, we can create the connector.
Sink Connector
“Lenses S3 Connector is a Kafka Connect sink connector for writing records from Kafka to AWS S3 Buckets. It extends the standard connect config adding a parameter for a SQL command (Lenses Kafka Connect Query Language or “KCQL”). This defines how to map data from the source (in this case Kafka) to the target (S3). Importantly, it also includes how data should be partitioned into S3, the bucket names and the serialization format (support includes JSON, Avro, Parquet, Text, CSV and binary).”
I find the Lenses S3 connector is more straightforward to configure than the Confluent S3 sink connector for its SQL-like syntax. The KCQL configuration indicates that object files are set to be
moved from a Kafka topic (demo.datalake.cdc_events) to an S3 bucket (data-lake-demo-cevo) with object prefix of cdc-events-local,
partitioned by customer_id and order_id eg) customer_id=<customer-id>/order_id=<order-id>,
stored as the JSON format and,
flushed every 60 seconds or when there are 50 records.
# ./connector/msk/sink-s3-lenses.properties |
We can create the sink connector on AWS Console using the same steps to the source connector.
Update/Insert Examples
Kafka UI
When we used the Confluent platform for local development in the previous post, we checked topics and messages on the control tower UI. For MSK, we can use Kafka UI. Below shows a docker-compose file for it. Note that the MSK cluster is secured by IAM Authentication so that AWS_MSK_IAM is specified as the SASL mechanism. Under the hood, it uses Amazon MSK Library for AWS IAM for authentication and AWS credentials are provided via volume mapping. Also don’t forget to connect the VPN bastion host using the SoftEther VPN client program.
# ./kafka-ui/docker-compose.yml version: “2” |
Once started, the UI can be accessed via http://localhost:8080. We see that the CDC topic is found in the topics list. There are 829 messages in the topic and it matches the number of records in the cdc_events table at creation.
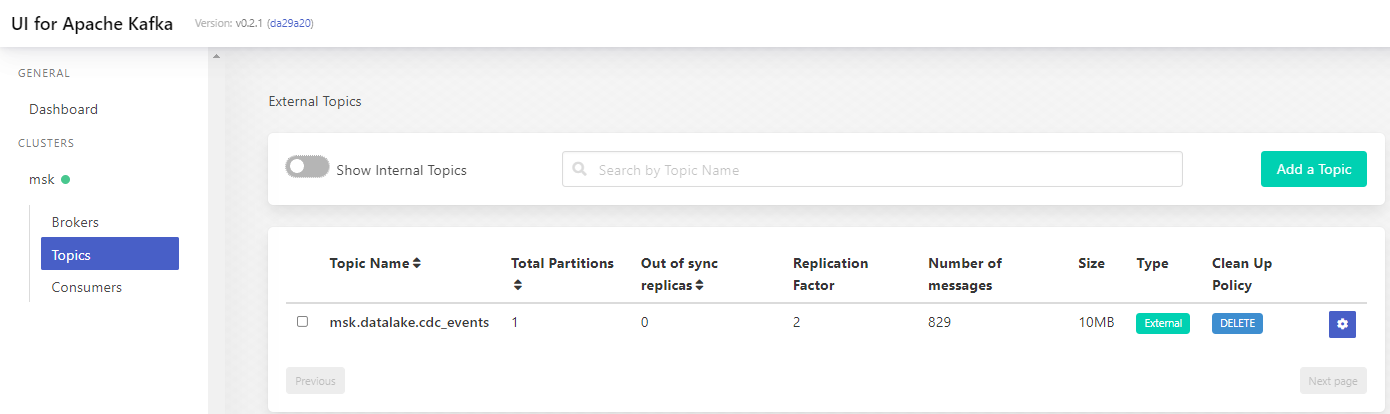
When we click the topic name, it shows further details of it. When clicking the messages tab, we can see individual messages within the topic. The UI also has some other options and it can be convenient to manage topics and messages.
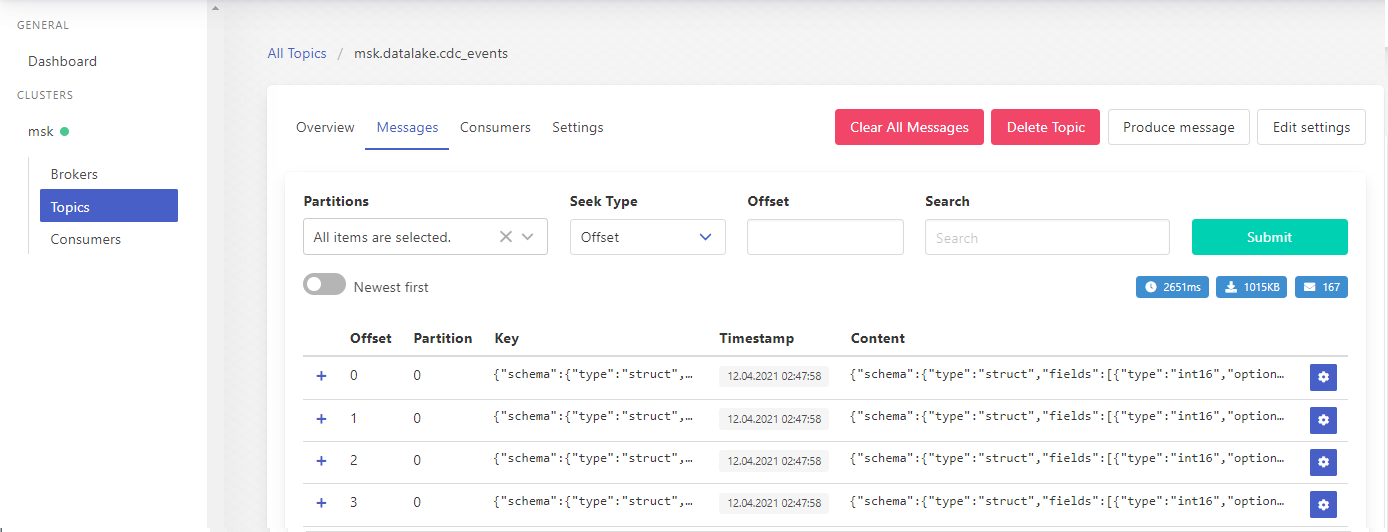
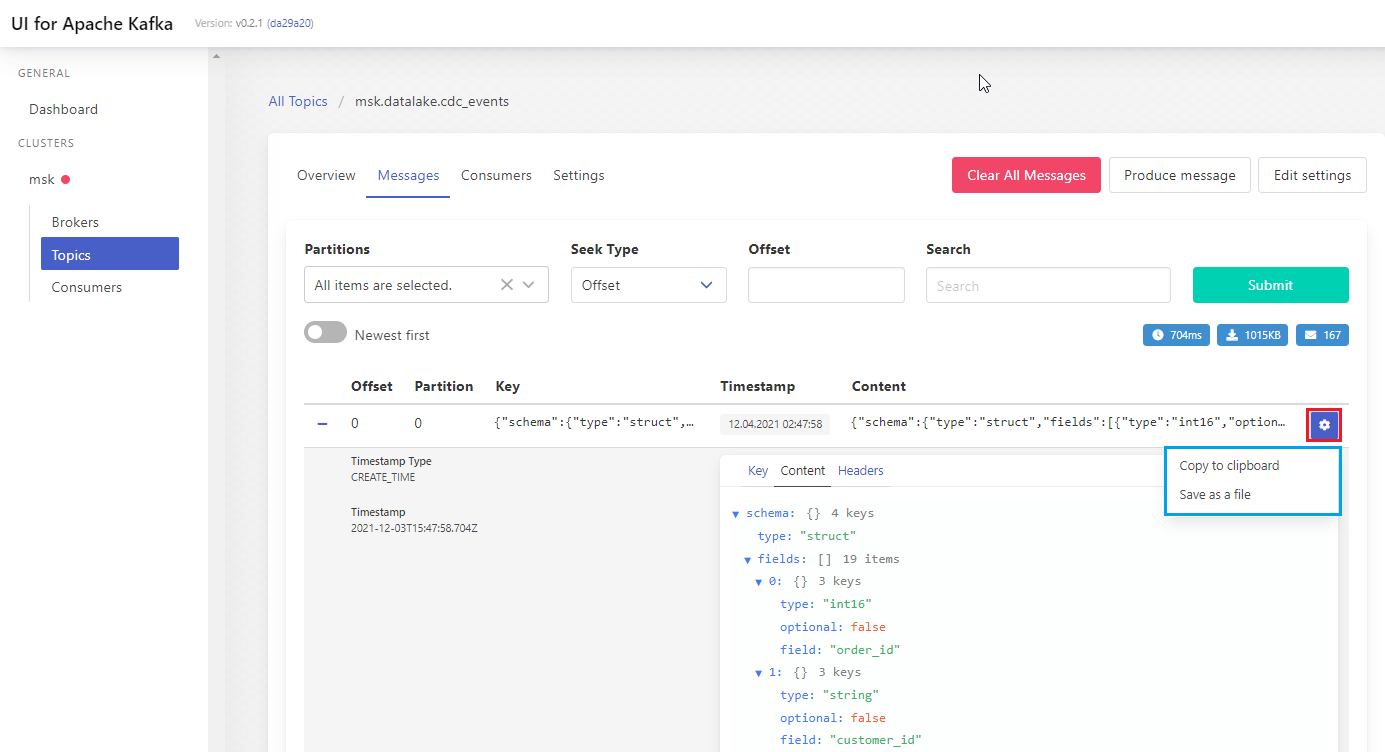
The message records can be expanded and we can check a message’s key, content and headers. Also we can either copy the value to clipboard or save as a file.
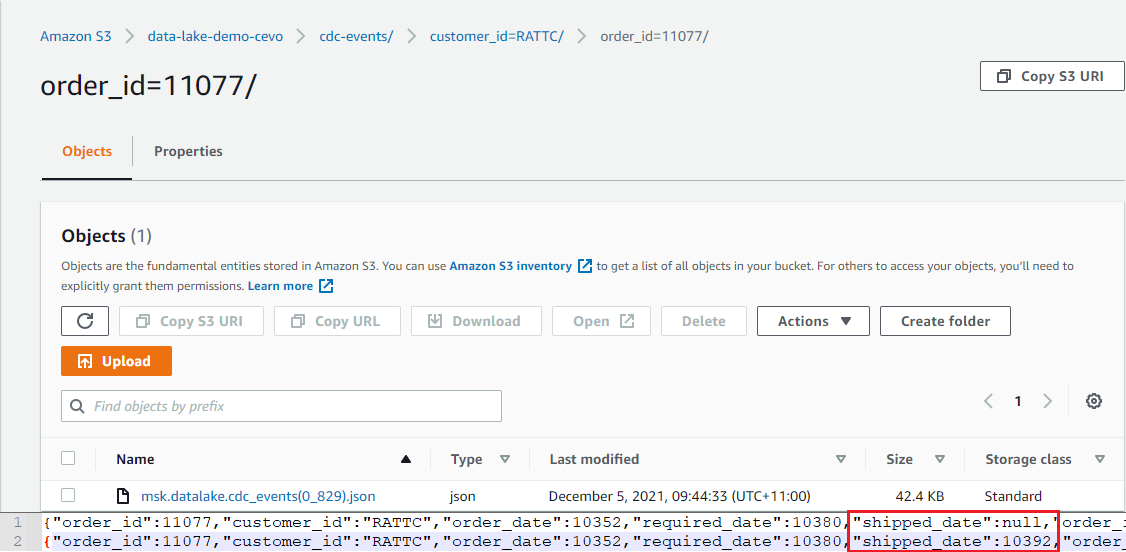
Update Event
The order 11077 initially didn’t have the shipped_date value. When the value is updated later, a new output file will be generated with the updated value.
BEGIN TRANSACTION; |
In S3, we see 2 JSON objects are included in the output file for the order entry and the shipped_date value is updated as expected. Note that the Debezium connector converts the DATE type to the INT32 type, which represents the number of days since the epoch.
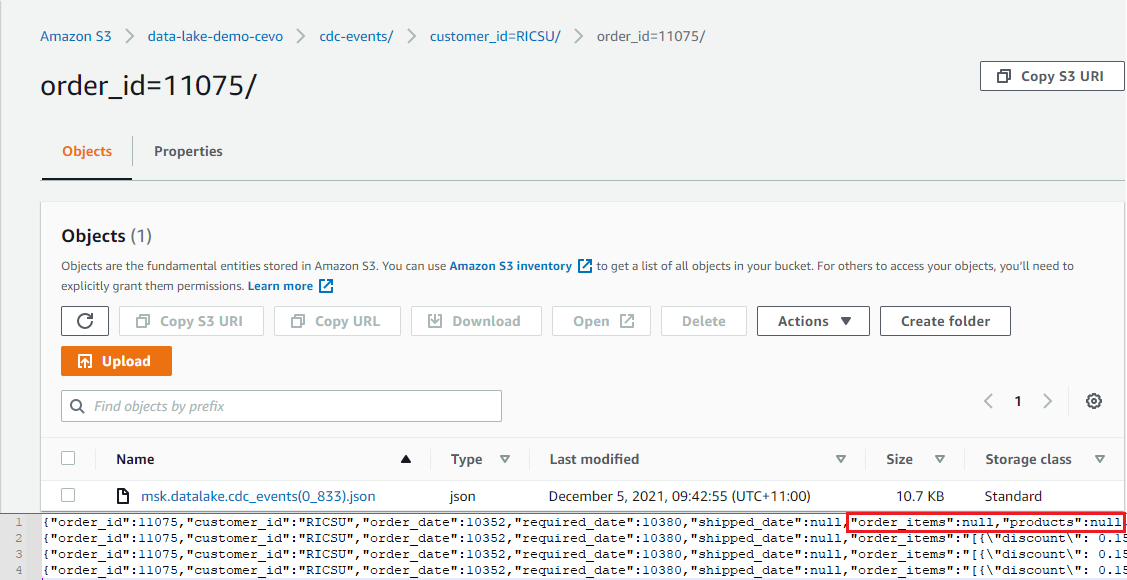
Insert Event
When a new order is created, it’ll insert a record to the orders table as well as one or more order items to the order_details table. Therefore we expect multiple event records will be created when a new order is created. We can check it by inserting an order and related order details items.
BEGIN TRANSACTION; |
We can see the output file includes 4 JSON objects where the first object has NULL order_items and products value. We can also see that those values are expanded gradually in subsequent event records.
Conclusion
We created a VPC that has private and public subnets in 2 availability zones in order to build and deploy the data lake solution on AWS. NAT instances are created to forward outbound traffic to the internet and a VPN bastion host is set up to facilitate deployment. An Aurora PostgreSQL cluster is deployed to host the source database and a Python command line app is used to create the database. To develop data ingestion using CDC, a MSK cluster is deployed and the Debezium source and Lenses S3 sink connectors are created on MSK Connect. We also confirmed the order creation and update events are captured as expected with the scenarios used by local development. Using CDC event output files in S3, we are able to build an Apache Hudi table on EMR and use it for ad-hoc queries and report/dashboard generation using Athena and Quicksight. It’ll be covered in the next post.



