In the previous post, we created a VPC that has private and public subnets in 2 availability zones in order to build and deploy the data lake solution on AWS. NAT instances are created to forward outbound traffic to the internet and a VPN bastion host is set up to facilitate deployment. An Aurora PostgreSQL cluster is deployed to host the source database and a Python command line app is used to create the database. To develop data ingestion using CDC, an Amazon MSK cluster is deployed and the Debezium source and Lenses S3 sink connectors are created on MSK Connect. We also confirmed the order creation and update events are captured as expected. As the last part of this series, we’ll build an Apache Hudi DeltaStramer app on Amazon EMR and use the resulting Hudi table with Amazon Athena and Amazon Quicksight to build a dashboard.
Architecture
As described in a Red Hat IT topics article, change data capture (CDC) is a proven data integration pattern to track when and what changes occur in data then alert other systems and services that must respond to those changes. Change data capture helps maintain consistency and functionality across all systems that rely on data.
The primary use of CDC is to enable applications to respond almost immediately whenever data in databases change. Specifically its use cases cover microservices integration, data replication with up-to-date data, building time-sensitive analytics dashboards, auditing and compliance, cache invalidation, full-text search and so on. There are a number of approaches for CDC – polling, dual writes and log-based CDC. Among those, log-based CDC has advantages to other approaches.
Both Amazon DMS and Debezium implement log-based CDC. While the former is a managed service, the latter can be deployed to a Kafka cluster as a (source) connector. It uses Apache Kafka as a messaging service to deliver database change notifications to the applicable systems and applications. Note that Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems by connectors. In AWS, we can use Amazon MSK and MSK Connect for building a Debezium based CDC solution.
Data replication to data lakes using CDC can be much more effective if data is stored to a format that supports atomic transactions and consistent updates. Popular choices are Apache Hudi, Apache Iceberg and Delta Lake. Among those, Apache Hudi can be a good option as it is well-integrated with AWS services.
Below shows the architecture of the data lake solution that we will be building in this series of posts.
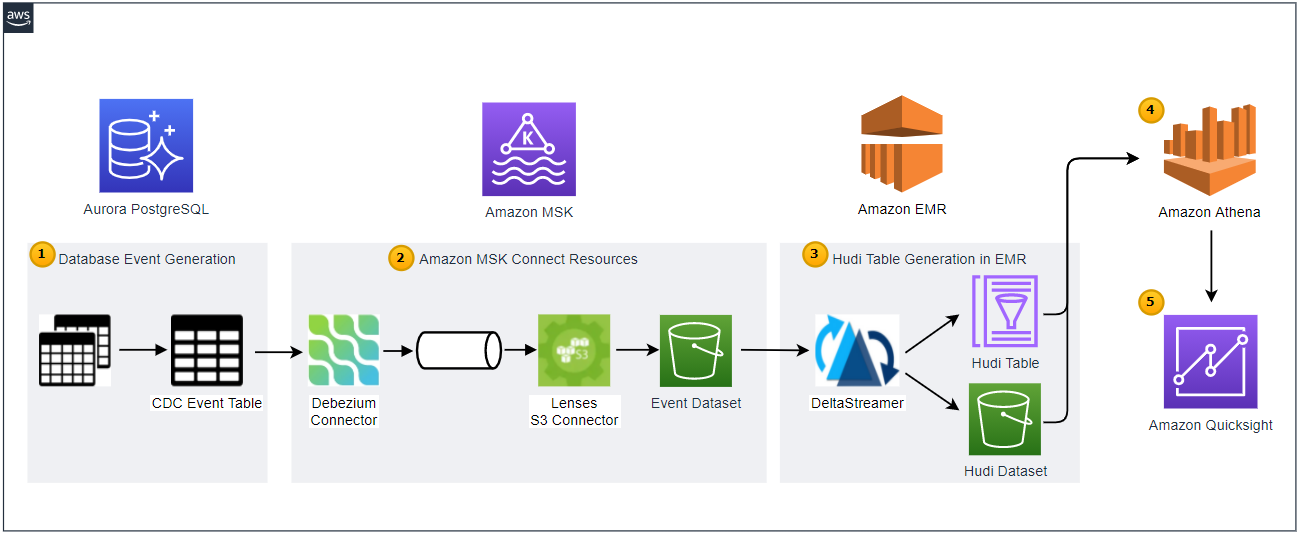
Employing the transactional outbox pattern, the source database publishes change event records to the CDC event table. The event records are generated by triggers that listen to insert and update events on source tables. See the Source Database section of the first post of this series for details.
CDC is implemented in a streaming environment and Amazon MSK is used to build the streaming infrastructure. In order to process the real-time CDC event records, a source and sink connectors are set up in Amazon MSK Connect. The Debezium connector for PostgreSQL is used as the source connector and the Lenses S3 connector is used as the sink connector. The sink connector pushes messages to a S3 bucket.
Hudi DeltaStreamer is run on Amazon EMR. As a spark application, it reads files from the S3 bucket and upserts Hudi records to another S3 bucket. The Hudi table is created in the AWS Glue Data Catalog.
The Hudi table is queried in Amazon Athena while the table is registered in the AWS Glue Data Catalog.
Dashboards are created in Amazon Quicksight where the dataset is created using Amazon Athena.
In this post, we’ll build a Hudi DeltaStramer app on Amazon EMR and use the resulting Hudi table with Athena and Quicksight to build a dashboard.
Infrastructure
In the previous post, we created a VPC in the Sydney region, which has private and public subnets in 2 availability zones. We also created NAT instances in each availability zone to forward outbound traffic to the internet and a VPN bastion host to access resources in the private subnets. An EMR cluster will be deployed to one of the private subnets of the VPC.
EMR Cluster
We’ll create the EMR cluster with the following configurations.
It is created with the latest EMR release – emr-6.4.0.
It has 1 master and 2 core instance groups – their instance types are m4.large.
Both the instance groups have additional security groups that allow access from the VPN bastion host.
It installs Hadoop, Hive, Spark, Presto, Hue and Livy.
It uses the AWS Glue Data Catalog as the metastore for Hive and Spark.
The last configuration is important to register the Hudi table to the Glue Data Catalog so that it can be accessed from other AWS services such as Athena and Quicksight. The cluster is created by CloudFormation and the template also creates a Glue database (datalake) in which the Hudi table will be created. The template can be found in the project GitHub repository.
Once the EMR cluster is ready, we can access the master instance as shown below. Note don’t forget to connect the VPN bastion host using the SoftEther VPN client program.
Hudi Table
Source Schema
Kafka only transfers data in byte format and data verification is not performed at the cluster level. As producers and consumers do not communicate with each other, we need a schema registry that sits outside of a Kafka cluster and handles distribution of schemas. Although it is recommended to associate with a schema registry, we avoid using it because it requires either an external service or a custom server to host a schema registry. Ideally it’ll be good if we’re able to use the AWS Glue Schema Registry but unfortunately it doesn’t support a REST interface and cannot be used at the moment.
In order to avoid having a schema registry, we use the built-in Json converter (org.apache.kafka.connect.json.JsonConverter) as the key and value converters for the Debezium source and S3 sink connectors. The resulting value schema of our CDC event message is of the struct type and it can be found in the project GitHub repository. However it is not supported by the DeltaStreamer utility that we’ll be using to generate the Hudi table. A quick fix is replacing it with the Avro schema and we can generate it with the local docker-compose environment that we discussed in the first post of this series. Once the local environment is up and running, we can create the Debezium source connector with the Avro converter (io.confluent.connect.avro.AvroConverter) as shown below.
curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” \ |
Then we can download the value schema in the Schema tab of the topic.
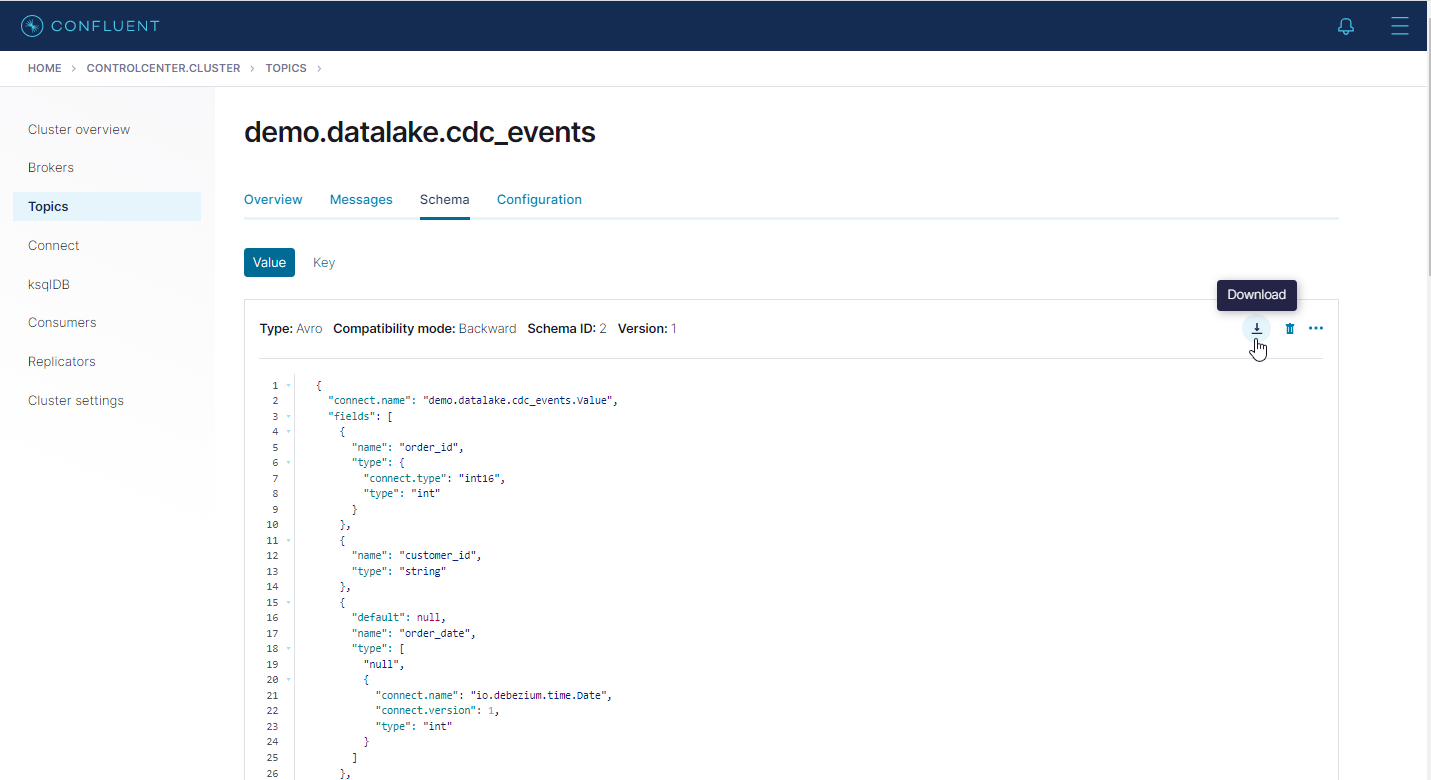
The schema file of the CDC event messages can be found in the project GitHub repository. Note that, although we use it as the source schema file for the DeltaStreamer app, we keep using the Json converter for the Kafka connectors as we don’t set up a schema registry.
DeltaStreamer
The HoodieDeltaStreamer utility (part of hudi-utilities-bundle) provides the way to ingest from different sources such as DFS or Kafka, with the following capabilities.
Exactly once ingestion of new events from Kafka, incremental imports from Sqoop or output of HiveIncrementalPuller or files under a DFS folder
Support json, avro or a custom record types for the incoming data
Manage checkpoints, rollback & recovery
Leverage Avro schemas from DFS or Confluent schema registry.
Support for plugging in transformations
As shown below, it runs as a Spark application. Some important options are illustrated below.
Hudi-related jar files are specified directly because Amazon EMR release version 5.28.0 and later installs Hudi components by default.
It is deployed by the cluster deploy mode where the driver and executor have 2G and 4G of memory respectively.
Copy on Write (CoW) is configured as the storage type.
Additional Hudi properties are saved in S3 (cdc_events_deltastreamer_s3.properties) – it’ll be discussed below.
The Json type is configured as the source file type – note we use the built-in Json converter for the Kafka connectors.
The S3 target base path indicates the place where the Hudi data is stored and the target table configures the resulting table.
As we enable the AWS Glue Data Catalog as the Hive metastore, it can be accessed in Glue.
The file-based schema provider is configured.
The Avro schema file is referred to as the source schema file in the additional Hudi property file.
Hive sync is enabled and the minimum sync interval is set to 5 seconds.
It is set to run continuously and the default UPSERT operation is chosen.
spark-submit –jars /usr/lib/spark/external/lib/spark-avro.jar,/usr/lib/hudi/hudi-utilities-bundle.jar \ |
Below shows the additional Hudi properties. For Hive sync, the database, table, partition fields and JDBC URL are specified. Note that the private IP address of the master instance is added to the host of the JDBC URL. It is required when submitting the application by the cluster deploy mode. By default, the host is set to localhost and the connection failure error will be thrown if the app doesn’t run in the master. The remaining Hudi datasource properties are to configure the primary key of the Hudi table – every record in Hudi is uniquely identified by a pair of record key and partition path fields. The Hudi DeltaStreamer properties specify the source schema file and the S3 location where the source data files exist. More details about the configurations can be found in the Hudi website.
# ./hudi/config/cdc_events_deltastreamer_s3.properties ## base properties |
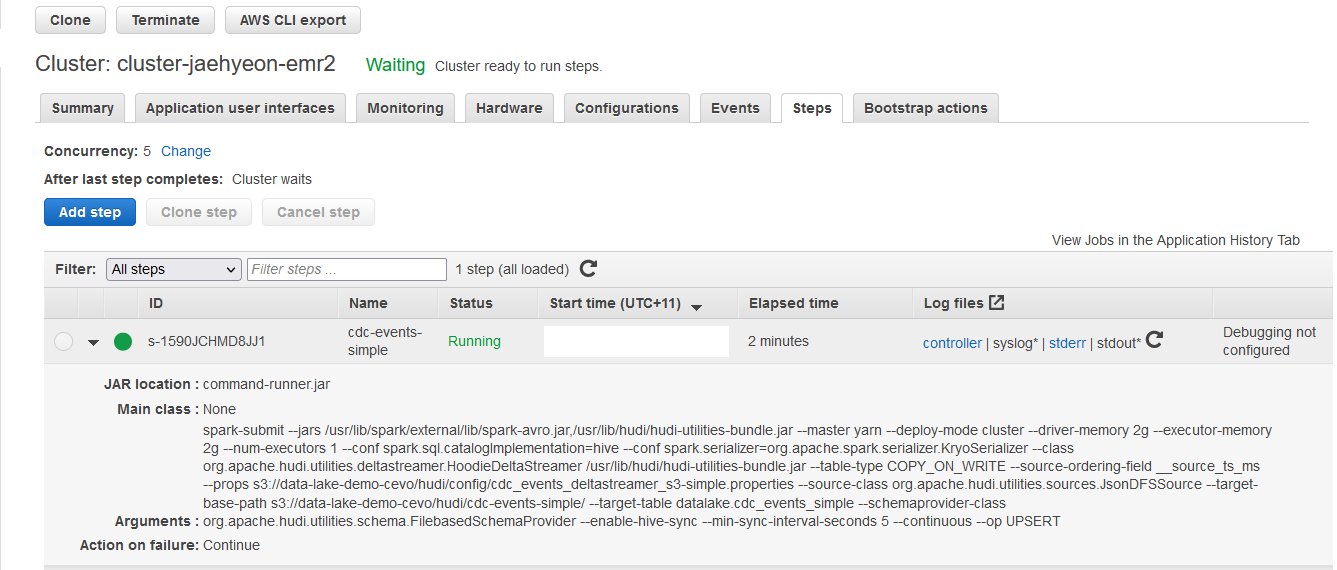
EMR Steps
While it is possible to submit the application in the master instance, it can also be submitted as an EMR step. As an example, a simple version of the app is submitted as shown below. The Json file that configures the step can be found in the project GitHub repository.
aws emr add-steps \ |
Once the step is added, we can see its details on the EMR console.
Glue Table
Below shows the Glue tables that are generated by the DeltaStreamer apps. The main table (cdc_events) is by submitting the app on the master instance while the simple version is by the EMR step.

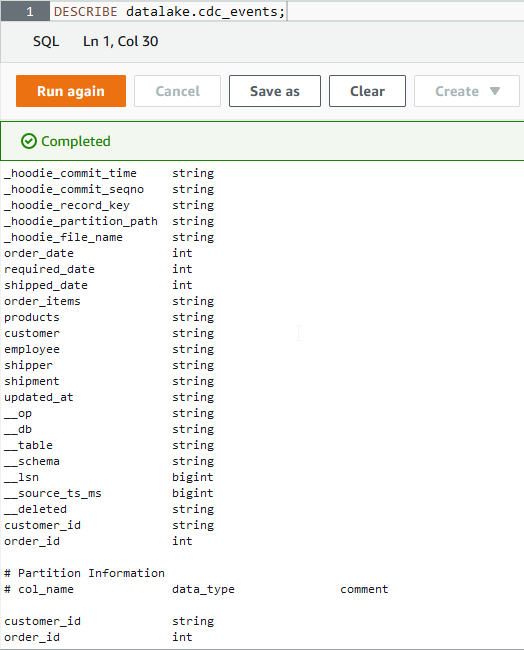
We can check the details of the table in Athena. When we run the describe query, it shows column and partition information. As expected, it has 2 partition columns and additional Hudi table meta information is included as extra columns.
Dashboard
Using the Glue table, we can create dashboards in Quicksight. As an example, a dataset of order items is created using Athena as illustrated in the Quicksight documentation. As the order items column in the source table is JSON, custom SQL is chosen so that it can be preprocessed in a more flexible way. The following SQL statement is used to create the dataset. First it parses the order items column and then flattens the array elements into rows. Also the revenue column is added as a calculated field.
WITH raw_data AS ( |
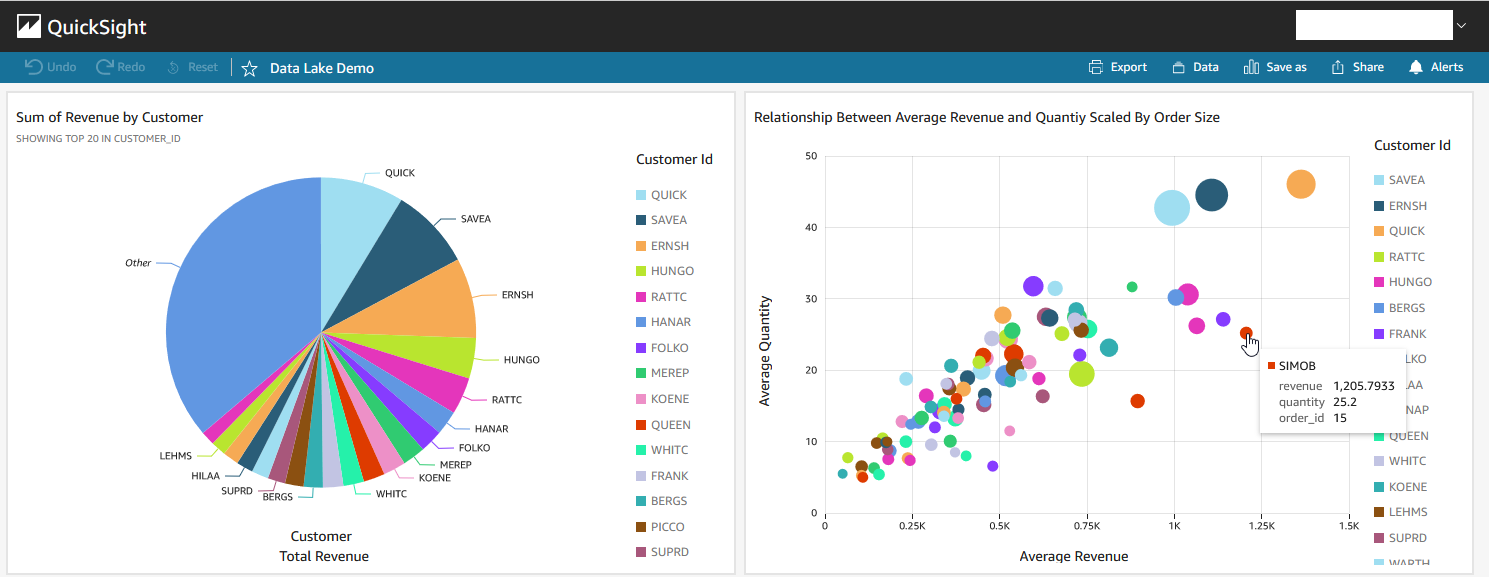
A demo dashboard is created using the order items dataset as shown below. The pie chart on the left indicates there are 3 big customers and the majority of revenue is earned by the top 20 customers. The scatter plot on the right shows a more interesting story. It marks the average quantity and revenue by customers and the dots are scaled by the number of orders – the more orders, the larger the size of the dot. While the 3 big customers occupy the top right area, 5 potentially profitable customers are identified. They do not purchase frequently but tend to buy expensive items, resulting in the average revenue being higher. We may investigate them further if a promotional event may be appropriate to make them purchase more frequently in the future.
Conclusion
In this post, we created an EMR cluster and developed a DeltaStramer app that can be used to upsert records to a Hudi table. Being sourced as a Athena dataset, the records of the table are used by a Quicksight dashboard. Over the series of posts we have built an effective end-to-end data lake solution while combining various AWS services and open source tools. The source database is hosted in an Aurora PostgreSQL cluster and a change data capture (CDC) solution is built on Amazon MSK and MSK Connect. With the CDC output files in S3, a DeltaStreamer app is developed on Amazon EMR to build a Hudi table. The resulting table is used to create a dashboard with Amazon Athena and Quicksight.



