Amazon EMR is a managed service that simplifies running Apache Spark on AWS. It has multiple deployment options that cover EC2, EKS, Outposts and Serverless. For development and testing, EMR Notebooks or EMR Studio can be an option. Both provide a Jupyter Notebook environment and the former is only available for EMR on EC2. There are cases, however, that development (and learning) is performed in a local environment more efficiently. The AWS Glue team understands this demand and they illustrate how to make use of a custom Docker image for Glue in a recent blog post. However we don’t hear similar news from the EMR team. In order to fill the gap, we’ll discuss how to create a Spark local development environment for EMR using Docker and/or VSCode. Typical Spark development examples will be demonstrated, which covers Spark Submit, pytest, PySpark shell, Jupyter Notebook and Spark Structured Streaming. For the Spark Submit and Jupyter Notebook examples, Glue Catalog integration will be illustrated as well. And both the cases of utilising Visual Studio Code Remote – Containers extension and running as an isolated container will be covered in some key examples.
Custom Docker Image
While we may build a custom Spark Docker image from scratch, it’ll be tricky to configure the AWS Glue Data Catalog as the metastore for Spark SQL. Note that it is important to set up this feature because it can be used to integrate other AWS services such as Athena, Glue, Redshift Spectrum and so on. For example, with this feature, we can create a Glue table using a Spark application and the table can be queried by Athena or Redshift Spectrum.
Instead we can use one of the Docker images for EMR on EKS as a base image and build a custom image from it. As indicated in the EMR on EKS document, we can pull an EMR release image from ECR. Note to select the right AWS account ID as it is different from one region to another. After authenticating to the ECR repository, I pulled the latest EMR 6.5.0 release image.
## different aws region has a different account id $ aws ecr get-login-password –region ap-southeast-2 \ ## download the latest release (6.5.0) $ docker pull 038297999601.dkr.ecr.ap-southeast-2.amazonaws.com/spark/emr-6.5.0:20211119 |
In the Dockerfile, I updated the default user (hadoop) to have the admin privilege as it can be handy to modify system configuration if necessary. Then spark-defaults.conf and log4j.properties are copied to the Spark configuration folder – they’ll be discussed in detail below. Finally a number of python packages are installed. Among those, the ipykernel and python-dotenv packages are installed to work on Jupyter Notebooks and the pytest and pytest-cov packages are for testing. The custom Docker image is built with the following command: docker build -t=emr-6.5.0:20211119 .devcontainer/.
# .devcontainer/Dockerfile FROM 038297999601.dkr.ecr.ap-southeast-2.amazonaws.com/spark/emr-6.5.0:20211119 |
In the default spark configuration file (spark-defaults.conf) shown below, I commented out the following properties that are strictly related to EMR on EKS.
spark.master
spark.submit.deployMode
spark.kubernetes.container.image.pullPolicy
spark.kubernetes.pyspark.pythonVersion
Then I changed the custom AWS credentials provider class from WebIdentityTokenCredentialsProvider to EnvironmentVariableCredentialsProvider. Note EMR jobs are run by a service account on EKS and authentication is managed by web identity token credentials. In a local environment, however, we don’t have an identity provider to authenticate so that access via environment variables can be an easy alternative option. We need the following environment variables to access AWS resources.
AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY
AWS_SESSION_TOKEN
note it is optional and required if authentication is made via assume role
AWS_REGION
note it is NOT AWS_DEFAULT_REGION
Finally I enabled Hive support and set AWSGlueDataCatalogHiveClientFactory as the Hive metastore factory class. When we start an EMR job, we can override application configuration to use AWS Glue Data Catalog as the metastore for Spark SQL and these are the relevant configuration changes for it.
# .devcontainer/spark/spark-defaults.conf … #spark.master k8s://https://kubernetes.default.svc:443 |
Even if the credentials provider class is changed, it keeps showing long warning messages while fetching EC2 metadata. The following lines are added to the Log4j properties in order to disable those messages.
# .devcontainer/spark/log4j.properties … ## Ignore warn messages related to EC2 metadata access failure |
VSCode Development Container
We are able to run Spark Submit, pytest, PySpark shell examples as an isolated container using the custom Docker image. However it can be much more convenient if we are able to perform development inside the Docker container where our app is executed. The Visual Studio Code Remote – Containers extension allows you to open a folder inside a container and to use VSCode’s feature sets. It supports both a standalone container and Docker Compose. In this post, we’ll use the latter as we’ll discuss an example Spark Structured Streaming application and multiple services should run and linked together for it.
Docker Compose
The main service (container) is named spark and its command prevents it from being terminated. The current working directory is mapped to /home/hadoop/repo and it’ll be the container folder that we’ll open for development. The aws configuration folder is volume-mapped to the container user’s home directory. It is an optional configuration to access AWS services without relying on AWS credentials via environment variables. The remaining services are related to Kafka. The kafka and zookeeper services are to run a Kafka cluster and the kafka-ui allows us to access the cluster on a browser. The services share the same Docker network named spark. Note that the compose file includes other Kafka related services and their details can be found in one of my earlier posts.
# .devcontainer/docker-compose.yml version: “2” … …
|
Development Container
The development container is configured to connect the spark service among the Docker Compose services. The AWS_PROFILE environment variable is optionally set for AWS configuration and additional folders are added to PYTHONPATH, which is to use the bundled pyspark and py4j packages of the Spark distribution. The port 4040 for Spark History Server is added to the forwarded ports array – I guess it’s optional as the port is made accessible in the compose file. The remaining sections are for installing VSCode extensions and adding editor configuration. Note we need the Python extension (ms-python.python) not only for code formatting but also for working on Jupyter Notebooks.
# .devcontainer/devcontainer.json { |
We can open the current folder in the development container after launching the Docker Compose services by executing the following command in the command palette.
Remote-Containers: Open Folder in Container…

Once the development container is ready, the current folder will be open within the spark service container. We are able to check the container’s current folder is /home/hadoop/repo and the container user is hadoop.

File Permission Management
I use Ubuntu in WSL 2 for development and the user ID and group ID of my WSL user are 1000. On the other hand, the container user is hadoop and its user ID and group ID are 999 and 1000 respectively. When you create a file in the host, the user has the read and write permissions of the file while the group only has the read permission. Therefore you can read the file inside the development container by the container user but it is not possible to modify it due to lack of the write permission. This file permission issue will happen when a file is created by the container user and the WSL user tries to modify it in the host. A quick search shows this is a typical behaviour applicable only to Linux (not Mac or Windows).
In order to handle this file permission issue, we can update the file permission so that the read and write permissions are given to both the user and group. Note the host (WSL) user and container user have the same group ID and writing activities will be allowed at least by the group permission. Below shows an example. The read and write permissions for files in the project folder are given to both the user and group. Those that are created by the container user indicate the user name while there are 2 files that are created by the WSL user and it is indicated by the user ID because there is no user whose user ID is 1000 in the container.
bash-4.2$ ls -al | grep ‘^-‘ |
Below is the same file list that is printed in the host. Note that the group name is changed into the WSL user’s group and those that are created by the container user are marked by the user ID.
jaehyeon@cevo:~/personal/emr-local-dev$ ls -al | grep ‘^-‘ |
We can add the read or write permission of a single file or a folder easily as shown below – g+rw. Note the last example is for the AWS configuration folder and only the read access is given to the group. Note also that file permission change is not affected if the repository is cloned into a new place and thus it only affects the local development environment.
# add write access of a file to the group # add write access of a folder to the group # add read access of the .aws folder to the group |
Examples
In this section, I’ll demonstrate typical Spark development examples. They’ll cover Spark Submit, pytest, PySpark shell, Jupyter Notebook and Spark Structured Streaming. For the Spark Submit and Jupyter Notebook examples, Glue Catalog integration will be illustrated as well. And both the cases of utilising Visual Studio Code Remote – Containers extension and running as an isolated container will be covered in some key examples.
Spark Submit
It is a simple Spark application that reads a sample NY taxi trip dataset from a public S3 bucket. Once loaded, it converts the pick-up and drop-off datetime columns from string to timestamp followed by writing the transformed data to a destination S3 bucket. The destination bucket name (bucket_name) can be specified by a system argument or its default value is taken. It finishes by creating a Glue table and, similar to the destination bucket name, the table name (tblname) can be specified as well.
# tripdata.py import sys |
The Spark application can be submitted as shown below.
export AWS_ACCESS_KEY_ID=<AWS-ACCESS-KEY-ID> export AWS_REGION=<AWS-REGION> # optional |
Once it completes, the Glue table will be created and we can query it using Athena as shown below.

If we want to submit the application as an isolated container, we can use the custom image directly. Below shows the equivalent Docker run command.
docker run –rm \ |
Pytest
The Spark application in the earlier example uses a custom function that converts the data type of one or more columns from string to timestamp – to_timestamp_df(). The source of the function and the testing script of it can be found below.
# utils.py from typing import List, Union
# test_utils.py |
As the test cases don’t access AWS services, they can be executed simply by the pytest command (eg pytest -v).

Testing can also be made in an isolated container as shown below. Note that we need to add the PYTHONPATH environment variable because we use the bundled pyspark package.
docker run –rm \ |
PySpark Shell
The PySpark shell can be launched as shown below.
$SPARK_HOME/bin/pyspark \ |
Also below shows an example of launching it as an isolated container.
docker run –rm -it \ |
Jupyter Notebook
Jupyter Notebook is a popular Spark application authoring tool and we can create a notebook simply by creating a file with the ipynb extension in VSCode. Note we need the ipykernel package in order to run code cells and it is already installed in the custom Docker image. For accessing AWS resources, we need the environment variables of AWS credentials mentioned earlier. We can use the python-dotenv package. Specifically we can create an .env file and add AWS credentials to it. Then we can add a code cell that loads the .env file at the beginning of the notebook.
In the next code cell, the app reads the Glue table and adds a column of trip duration followed by showing the summary statistics of key columns. We see some puzzling records that show zero trip duration or negative total amount. Among those, we find negative total amount records should be reported immediately and a Spark Structured Streaming application turns out to be a good option.


Spark Streaming
We need sample data that can be read by the Spark application. In order to generate it, the individual records are taken from the source CSV file and saved locally after being converted into json. Below script creates those json files in the data/json folder. Inside the development container, it can be executed as python3 data/generate.py.
# data/generate.py import shutil |
In the Spark streaming application, the steam reader loads json files in the data/json folder and the data schema is provided by DDL statements. Then it generates the target dataframe that filters records whose total amount is negative. Note the target dataframe is structured to have the key and value columns, which is required by Kafka. Finally it writes the records of the target dataframe to the notifications topics of the Kafka cluster.
# tripdata_notify.py from pyspark.sql import SparkSession |
The streaming application can be submitted as shown below. Note the Kafak 0.10+ Source for Structured Streaming and its dependencies are added directly to the spark submit command as indicated by the official document.
$SPARK_HOME/bin/spark-submit \ |
We can check the topic via Kafka UI on port 8080. We see the notifications topic has 50 messages, which matches to the number that we obtained from the notebook.
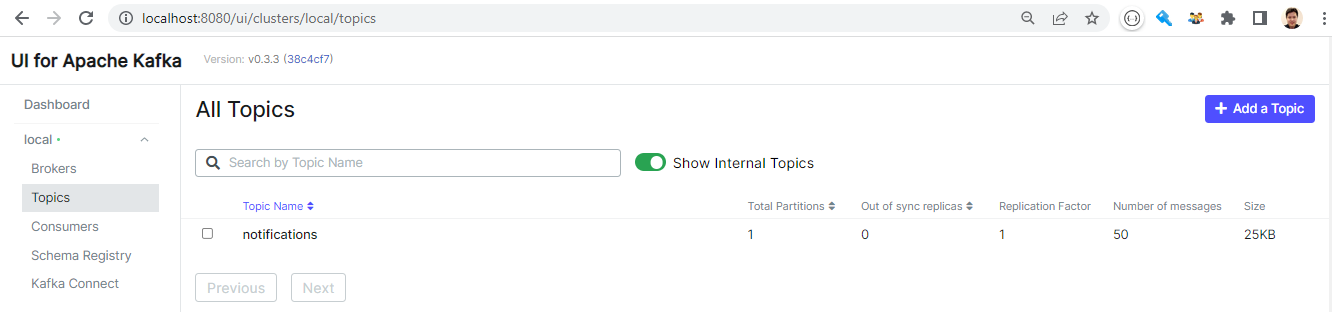
We can check the individual messages via the UI as well.

Summary
In this post, we discussed how to create a Spark local development environment for EMR using Docker and/or VSCode. A range of Spark development examples are demonstrated and Glue Catalog integration is illustrated in some of them. And both the cases of utilising Visual Studio Code Remote – Containers extension and running as an isolated container are covered in some key examples.



