EMR on EKS provides a deployment option for Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on Amazon EKS. While a wide range of open source big data components are available in EMR on EC2, only Apache Spark is available in EMR on EKS. It is more flexible, however, that applications of different EMR versions can be run in multiple availability zones on either EC2 or Fargate. Also other types of containerized applications can be deployed on the same EKS cluster. Therefore, if you have or plan to have, for example, Apache Airflow, Apache Superset or Kubeflow as your analytics toolkits, it can be an effective way to manage big data (as well as non-big data) workloads. While Glue is more for ETL, EMR on EKS can also be used for other types of tasks such as machine learning. Moreover it allows you to build a Spark application, not a Gluish Spark application. For example, while you have to use custom connectors for Hudi or Iceberg for Glue, you can use their native libraries with EMR on EKS. In this post, we’ll discuss EMR on EKS with simple and elaborated examples.
Cluster setup and configuration
We’ll use command line utilities heavily. The following tools are required.
AWS CLI V2 – it is the official command line interface that enables users to interact with AWS services.
eksctl – it is a CLI tool for creating and managing clusters on EKS.
kubectl – it is a command line utility for communicating with the cluster API server.
Upload preliminary resources to S3
We need supporting files and they are created/downloaded into the config and manifests folders using a setup script – the script can be found in the project GitHub repository. The generated files will be illustrated below.
export OWNER=jaehyeon |
We’ll configure logging on S3 and CloudWatch so that a S3 bucket and CloudWatch log group are created. Also a Glue database is created as I encountered an error to create a Glue table when the database doesn’t exist. Finally the files in the config folder are uploaded to S3.
#### create S3 bucket/log group/glue database and upload files to S3 |
Create EKS cluster and node group
We can use either command line options or a config file when creating a cluster or node group using eksctl. We’ll use config files and below shows the corresponding config files.
# ./config/cluster.yaml # ./config/nodegroup.yaml |
eksctl creates a cluster or node group via CloudFormation. Each command will create a dedicated CloudFormation stack and it’ll take about 15 minutes. Also it generates the default kubeconfig file in the $HOME/.kube folder. Once the node group is created, we can check it using the kubectl command.
#### create cluster, node group and configure |
Set up Amazon EMR on EKS
As described in the Amazon EMR on EKS development guide, Amazon EKS uses Kubernetes namespaces to divide cluster resources between multiple users and applications. A virtual cluster is a Kubernetes namespace that Amazon EMR is registered with. Amazon EMR uses virtual clusters to run jobs and host endpoints. The following steps are taken in order to set up for EMR on EKS.
Enable cluster access for Amazon EMR on EKS
After creating a Kubernetes namespace for EMR (spark), it is necessary to allow Amazon EMR on EKS to access the namespace. It can be automated by eksctl and specifically the following actions are performed.
setting up RBAC authorization by creating a Kubernetes role and binding the role to a Kubernetes user
mapping the Kubernetes user to the EMR on EKS service-linked role
kubectl create namespace spark |
While the details of the role and role binding can be found in the development guide, we can see that the aws-auth ConfigMap is updated with the new Kubernetes user.
kubectl describe cm aws-auth -n kube-system |
Create an IAM OIDC identity provider for the EKS cluster
We can associate an IAM role with a Kubernetes service account. This service account can then provide AWS permissions to the containers in any pod that uses that service account. Simply put, the service account for EMR will be allowed to assume the EMR job execution role by OIDC federation – see EKS user guide for details. The job execution role will be created below. In order for the OIDC federation to work, we need to set up an IAM OIDC provider for the EKS cluster.
eksctl utils associate-iam-oidc-provider \ |
Create a job execution role
The following job execution role is created for the examples of this post. The permissions are set up to perform tasks on S3 and Glue. We’ll also enable logging on S3 and CloudWatch so that the necessary permissions are added as well.
aws iam create-role \ |
Update the trust policy of the job execution role
As mentioned earlier, the EMR service account is allowed to assume the job execution role by OIDC federation. In order to enable it, we need to update the trust relationship of the role. We can update it as shown below.
aws emr-containers update-role-trust-policy \ |
Register Amazon EKS Cluster with Amazon EMR
We can register the Amazon EKS cluster with Amazon EMR as shown below. We need to provide the EKS cluster name and namespace.
## register EKS cluster with EMR |
We can also check the virtual cluster on the EMR console.

Examples
Food Establishment Inspection
This example is from the getting started tutorial of the Amazon EMR management guide. The PySpark script executes a simple SQL statement that counts the top 10 restaurants with the most Red violations and saves the output to S3. The script and its data source are saved to S3.
In the job request, we specify the job name, virtual cluster ID and job execution role. Also the spark submit details are specified in the job driver option where the entrypoint is set to the S3 location of the PySpark script, entry point arguments and spark submit parameters. Finally S3 and CloudWatch monitoring configuration is specified.
export VIRTUAL_CLUSTER_ID=$(aws emr-containers list-virtual-clusters –query “sort_by(virtualClusters, &createdAt)[-1].id” –output text) |
Once a job run is started, it can be checked under the virtual cluster section of the EMR console.
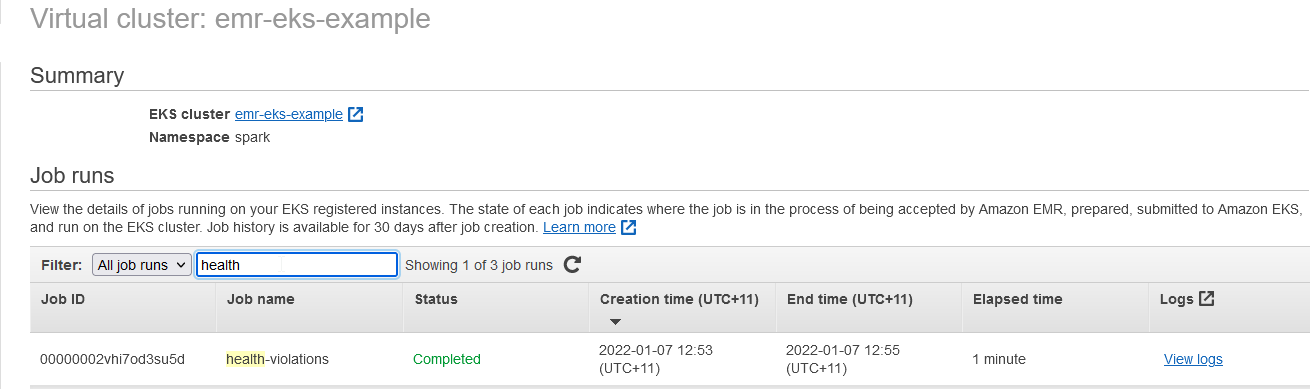
When we click the View logs link, it launches the Spark History Server on a new tab.

As configured, the container logs of the job can be found in CloudWatch.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.

Also the logs for the containers (spark driver and executor) and control-logs (job runner) can be found in S3.
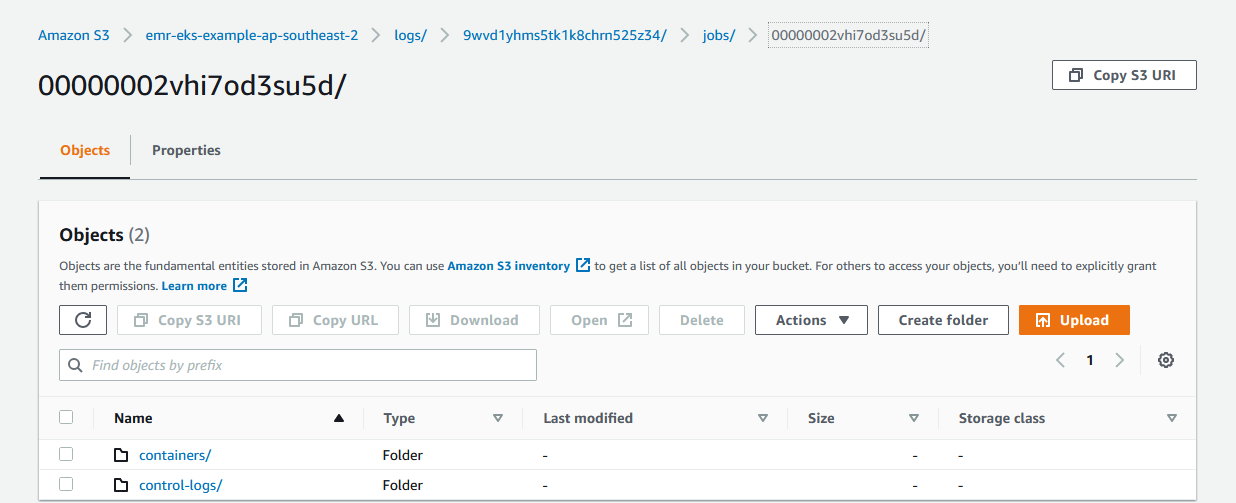
Once the job completes, we can check the output from S3 as shown below.
export OUTPUT_FILE=$(aws s3 ls s3://${S3_BUCKET_NAME}/output/ | grep .csv | awk ‘{print $4}’) |
Hudi DeltaStreamer
In an earlier post, we discussed a Hudi table generation using the DeltaStreamer utility as part of a CDC-based data ingestion solution. In that exercise, we executed the spark job in an EMR cluster backed by EC2 instances. We can run the spark job in our EKS cluster.
We can configure to run the executors in spot instances in order to save cost. A spot node group can be created by the following configuration file.
# ./manifests/nodegroup-spot.yaml — |
Once the spot node group is created, we can see 3 instances are added to the EKS node with the SPOT capacity type.
eksctl create nodegroup -f ./manifests/nodegroup-spot.yaml |
The driver and executor pods should be created in different nodes and it can be controlled by Pod Template. Below the driver and executor have a different node selector and they’ll be assigned based on the capacity type label specified in the node selector.
# ./config/driver_pod_template.yml |
The job request for the DeltaStreamer job can be found below. Note that, in the entrypoint, we specified the latest Hudi utilities bundle (0.10.0) from S3 instead of the pre-installed Hudi 0.8.0. It is because Hudi 0.8.0 supports JDBC based Hive sync only while Hudi 0.9.0+ supports multiple Hive sync modes including Hive metastore. EMR on EKS doesn’t run HiveServer2 so that JDBC based Hive sync doesn’t work. Instead we can specify Hive sync based on Hive metastore because Glue data catalog can be used as Hive metastore. Therefore we need a newer version of the Hudi library in order to register the resulting Hudi table to Glue data catalog. Also, in the application configuration, we configured to use Glue data catalog as the Hive metastore and the driver/executor pod template files are specified.
export VIRTUAL_CLUSTER_ID=$(aws emr-containers list-virtual-clusters –query “sort_by(virtualClusters, &createdAt)[-1].id” –output text) |
Once the job run is started, we can check it as shown below.
aws emr-containers list-job-runs –virtual-cluster-id ${VIRTUAL_CLUSTER_ID} –query “jobRuns[?name==’cdc-events’]” |
With kubectl, we can check there are 1 driver, 2 executors and 1 job runner pods.
kubectl get pod -n spark |
Also we can see the driver pod runs in the on-demand node group while the executor and job runner pods run in the spot node group.
## driver runs in the on demand node |
The Hudi utility will register a table in the Glue data catalog and it can be checked as shown below.
aws glue get-table –database-name datalake –name cdc_events \ |
Finally the details of the table can be queried in Athena.

Summary
In this post, we discussed how to run spark jobs on EKS. First we created an EKS cluster and a node group using eksctl. Then we set up EMR on EKS. A simple PySpark job that shows the basics of EMR on EKS is illustrated and a more realistic example of running Hudi DeltaStreamer utility is demonstrated where the driver and executors are assigned in different node groups.



