Artificial intelligence has come a long way in the last few years, and today, we’re seeing AI-based technologies being adopted in a wide range of industries and applications. From virtual assistants and self-driving cars to computer vision systems and decision-making systems, the potential for AI to transform the way we live and work is becoming increasingly clear. Deep learning, a type of machine learning that uses deep neural networks, also saw significant growth in popularity, as it enables solving of more complex problems. The availability of cloud-based AI tools and resources also increased, making it easier for businesses to access and use these technologies.
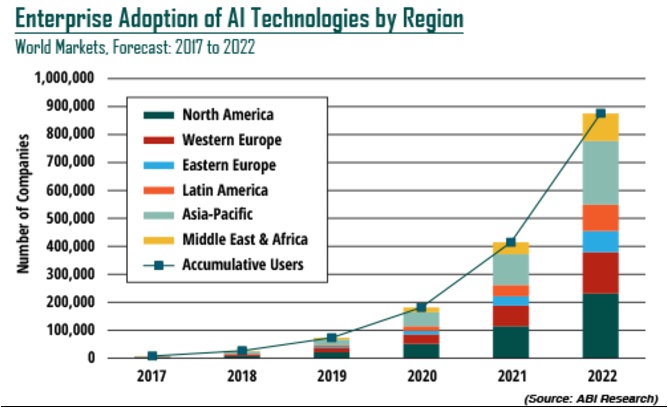
As the demand for skilled data professionals continues to grow, it’s important to understand the potential impact of machine learning on various industries. In part 1 of this blog series, we’ll explore the key ingredients that make for a successful machine learning use case. We’ll also discuss the importance of finding the right balance of speed, business value, data availability, and ML applicability when selecting a use case. Whether you are just getting started in machine learning or are part of a mature data team, we hope this blog will provide valuable insights and ideas to leverage the power of machine learning in your business.
At Cevo, we have spent thousands of hours solving data challenges that our customers face on a daily basis. As a result, we have identified four key ingredients for a successful machine learning use case:
- Data readiness: The use case should involve a high availability of data.
- Business impact: The use case should solve a real business problem and be important enough to the business to generate the necessary attention and resources.
- ML applicability: The use case should be suitable for machine learning and not just be ‘solving a problem that isn’t actually broken’.
- A clear plan for implementation and operationalisation: It is important to have a plan in place for how to implement and operationalise the machine learning use case.
Data Readiness
Data readiness refers to the availability of data for a potential machine learning use case, and is one of the key ingredients for a successful machine learning project.
Ensuring data readiness for machine learning can involve a wide variety of tasks, such as:
- Data collection: Gather all necessary data for the project. This includes identifying the type and amount of data needed, as well as any specific data sources that will be used.
- Data cleaning: Clean and preprocess the data to ensure that it is in a format that can be easily used by machine learning algorithms. This may include dealing with missing values, outliers, and inconsistencies in the data.
- Data exploration: Explore the data to gain a better understanding of its distribution, structure, and relationships between variables. This can be done using visualisations and statistical summaries.
- Data transformation: Transform the data as needed to improve its quality or make it more suitable for the specific machine learning task. This may include normalising or scaling the data, or creating new features from existing ones.
- Data splitting: Split the data into a training set, a validation set, and a test set. The training set is used to train the machine learning model, the validation set is used to evaluate the model during the training process, and the test set is used to evaluate the final performance of the model.
It is important to have a sufficient amount of high-quality data in order to build accurate and reliable machine learning models.
ML Applicability
ML applicability refers to the suitability of a potential use case for machine learning. In order to be successful, a machine learning project should address a problem that requires more than just a rule-based solution.
Some of the common use cases we have encountered in our conversations with customers are:
- Computer Vision: Examples of computer vision applications include self-driving cars, facial recognition, and image search.
- Natural Language Processing (NLP): Applications of NLP include language translation, text-to-speech synthesis, and sentiment analysis.
- Recommender Systems: This can be used in scenarios such as online shopping, movie or music streaming, and social media contents.
- Anomaly Detection: This can be used in applications such as fraud detection, intrusion detection and system monitoring.
- Predictive Maintenance: This can be used in applications such as manufacturing, power generation and transportation.
ML applicability can be evaluated by considering factors such as the complexity of the problem, the amount and quality of data available, and the feasibility of implementing a solution. A successful implementation should generate meaningful value to an organisation.
Business Impact
Business impact refers to the importance of a potential machine learning use case to the business. In order to be successful, a machine learning project should solve a real business problem and be important enough to the business to get the necessary attention and resources.
Below are some examples of machine learning solutions that have created business value:
- Fraud detection: A financial institution detecting fraudulent transactions, protecting the business from financial loss.
- Personalised marketing: A retail company analysing customer data and creating personalised marketing campaigns, increasing sales and customer loyalty.
- Supply chain optimisation: A logistics company optimising routes and scheduling, reducing transportation costs and improving delivery times.
- Sales forecasting: A retail company forecasting future sales, allowing for more accurate planning and budgeting.
- Employee retention: A human resources department analysing data on employee engagement and turnover, identifying factors that contribute to high retention rates and taking action to improve them.
- Chatbot customer service: A customer service department building a chatbot that can answer customer inquiries quickly and accurately, improving customer satisfaction.
These findings and optimisations ultimately can help organisations save energy, time, and resources, as well as minimise costs.
Plan for implementation and operationalisation
It is important to have a clear plan in place to successfully deploy and operate a machine learning project.
This involves considerations such as:
- Determining the appropriate resources: Assess the amount of data and computational power required for a machine learning project and invest in necessary hardware such as high-performance servers and storage.
- Setting up monitoring and evaluation systems: Establish metrics to evaluate the performance of the machine learning model, and set up systems to track and monitor these metrics.
- Defining roles and responsibilities: A clear definition of roles and responsibilities within a machine learning project to ensure tasks are divided and executed efficiently.
- Integration into the organisation: A well-designed plan to smoothly integrate a machine learning project into the organization can include providing training workshops for employees, involving relevant stakeholders in the planning and implementation process, and supporting the IT department in the adoption process.
- Long-term value: A plan for the ongoing maintenance and improvement of the machine learning project will help ensure it continues to provide value to the organisation in the long term.
In summary, machine learning is a powerful technology that is being applied in a variety of industries to solve real-world problems and drive business value. To successfully use machine learning, it is important to choose the right use case and have a clear plan for implementation and operationalisation. Using the simple framework described above, you can prioritise your AI/ML investment to maximise the value of the projects and increase your chances of success. In the second part of this blog series, we will apply this framework to an actual ML use case.



