Amazon EMR on EKS is a deployment option for Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on EKS. While eksctl is popular for working with Amazon EKS clusters, it has limitations when it comes to building infrastructure that integrates multiple AWS services. Also it is not straightforward to update EKS cluster resources incrementally with it. On the other hand Terraform can be an effective tool for managing infrastructure that includes not only EKS and EMR virtual clusters but also other AWS resources. Moreover Terraform has a wide range of modules and it can even be simpler to build and manage infrastructure using those compared to the CLI tool. In this post, we’ll discuss how to provision and manage Spark jobs on EMR on EKS with Terraform. Amazon EKS Blueprints for Terraform will be used for provisioning EKS, EMR virtual cluster and related resources. Also Spark job autoscaling will be managed by Karpenter where two Spark jobs with and without Dynamic Resource Allocation (DRA) will be compared.
Infrastructure
When a user submits a Spark job, multiple Pods (controller, driver and executors) will be deployed to the EKS cluster that is registered with EMR. In general, Karpenter provides just-in-time capacity for unschedulable Pods by creating (and terminating afterwards) additional nodes. We can configure the pod templates of a Spark job so that all the Pods are managed by Karpenter. In this way, we are able to run it only in transient nodes. Karpenter simplifies autoscaling by provisioning just-in-time capacity and it also reduces scheduling latency. The source can be found in the post’s GitHub repository.

VPC
Both private and public subnets are created in three availability zones using the AWS VPC module. The first two subnet tags are in relation to the subnet requirements and considerations of Amazon EKS. The last one of the private subnet tags (karpenter.sh/discovery) is added so that Karpenter can discover the relevant subnets when provisioning a node for Spark jobs.
# infra/main.tf |
EKS Cluster
Amazon EKS Blueprints for Terraform extends the AWS EKS module and it simplifies to create EKS clusters and Kubenetes add-ons. When it comes to EMR on EKS, it deploys the necessary resources to run EMR Spark jobs. Specifically it automates steps 4 to 7 of the setup documentation and it is possible to configure multiple teams (namespaces) as well. In the module configuration, only one managed node group (managed-ondemand) is created and it’ll be used to deploy all the critical add-ons. Note that Spark jobs will run in transient nodes, which are managed by Karpenter. Therefore we don’t need to create node groups for them.
# infra/main.tf module “eks_blueprints” { |
EMR Virtual Cluster
Terraform has the EMR virtual cluster resource and the EKS cluster can be registered with the associating namespace (analytics). It’ll complete the last step of the setup documentation.
# infra/main.tf resource “aws_emrcontainers_virtual_cluster” “analytics” { |
Kubernetes Add-ons
The Blueprints includes the kubernetes-addons module that simplifies deployment of Amazon EKS add-ons as well as Kubernetes add-ons. For scaling Spark jobs in transient nodes, Karpenter and AWS Node Termination Handler add-ons will be used mainly.
# infra/main.tf module “eks_blueprints_kubernetes_addons” { |
Karpenter
According to the AWS News Blog,
Karpenter is an open-source, flexible, high-performance Kubernetes cluster autoscaler built with AWS. It helps improve your application availability and cluster efficiency by rapidly launching right-sized compute resources in response to changing application load. Karpenter also provides just-in-time compute resources to meet your application’s needs and will soon automatically optimize a cluster’s compute resource footprint to reduce costs and improve performance.
Simply put, Karpeter adds nodes to handle unschedulable pods, schedules pods on those nodes, and removes the nodes when they are not needed. To configure Karpenter, we need to create provisioners that define how Karpenter manages unschedulable pods and expired nodes. For Spark jobs, we can deploy separate provisioners for the driver and executor programs
Spark Driver Provisioner
The labels contain arbitrary key-value pairs. As shown later, we can add it to the nodeSelector field of the Spark pod template. Then Karpenter provisions a node (if not existing) as defined by this Provisioner object. The requirements define which nodes to provision. Here 3 well-known labels are specified – availability zone, instance family and capacity type. The provider section is specific to cloud providers and, for AWS, we need to indicate InstanceProfile, LaunchTemplate, SubnetSelector or SecurityGroupSelector. Here we’ll use a launch template that keeps the instance group and security group ids. SubnetSelector is added separately as it is not covered by the launch template. Recall that we added a tag to private subnets (“karpenter.sh/discovery” = local.name) and we can use it here so that Karpenter discovers the relevant subnets when provisioning a node.
# infra/provisioners/spark-driver.yaml |
Spark Executor Provisioner
The executor provisioner configuration is similar except that it allows more instance family values and the capacity type value is changed into spot.
# infra/provisioners/spark-executor.yaml |
Terraform Resources
As mentioned earlier, a launch template is created for the provisioners and it includes the instance profile, security group id and additional configuration. The provisioner resources are created from the YAML manifests. Note we only select a single available zone in order to save cost and improve performance of Spark jobs.
# infra/main.tf |
Now we can deploy the infrastructure. Be patient until it completes.
Spark Job
A test spark app and pod templates are uploaded to a S3 bucket. The spark app is for testing autoscaling and it creates multiple parallel threads and waits for a few seconds – it is obtained from EKS Workshop. The pod templates basically select the relevant provisioners for the driver and executor programs. Two Spark jobs will run with and without Dynamic Resource Allocation (DRA). DRA is a Spark feature where the initial number of executors are spawned and then it is increased until the maximum number of executors is met to process the pending tasks. Idle executors are terminated when there are no pending tasks. This feature is particularly useful if we are not sure how many executors are necessary.
## upload.sh |
Without Dynamic Resource Allocation (DRA)
15 executors are configured to run for the Spark job without DRA. The application configuration is overridden to disable DRA and maps pod templates for the diver and executor programs.
export VIRTUAL_CLUSTER_ID=$(terraform –chdir=./infra output –raw emrcontainers_virtual_cluster_id) |
As indicated earlier, Karpenter can provide just-in-time compute resources to meet the Spark job’s requirements and we see that 3 new nodes are added accordingly. Note that, unlike cluster autoscaler, Karpenter provision nodes without creating a node group.
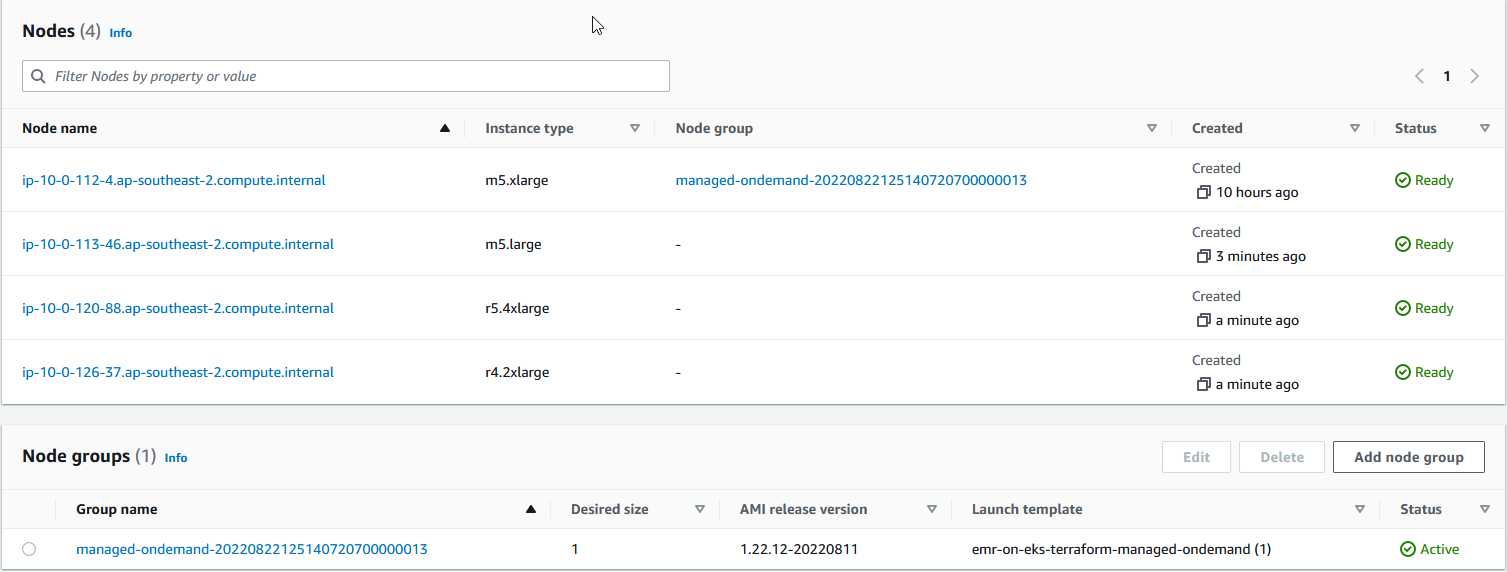
Once the job completes, the new nodes are terminated as expected.

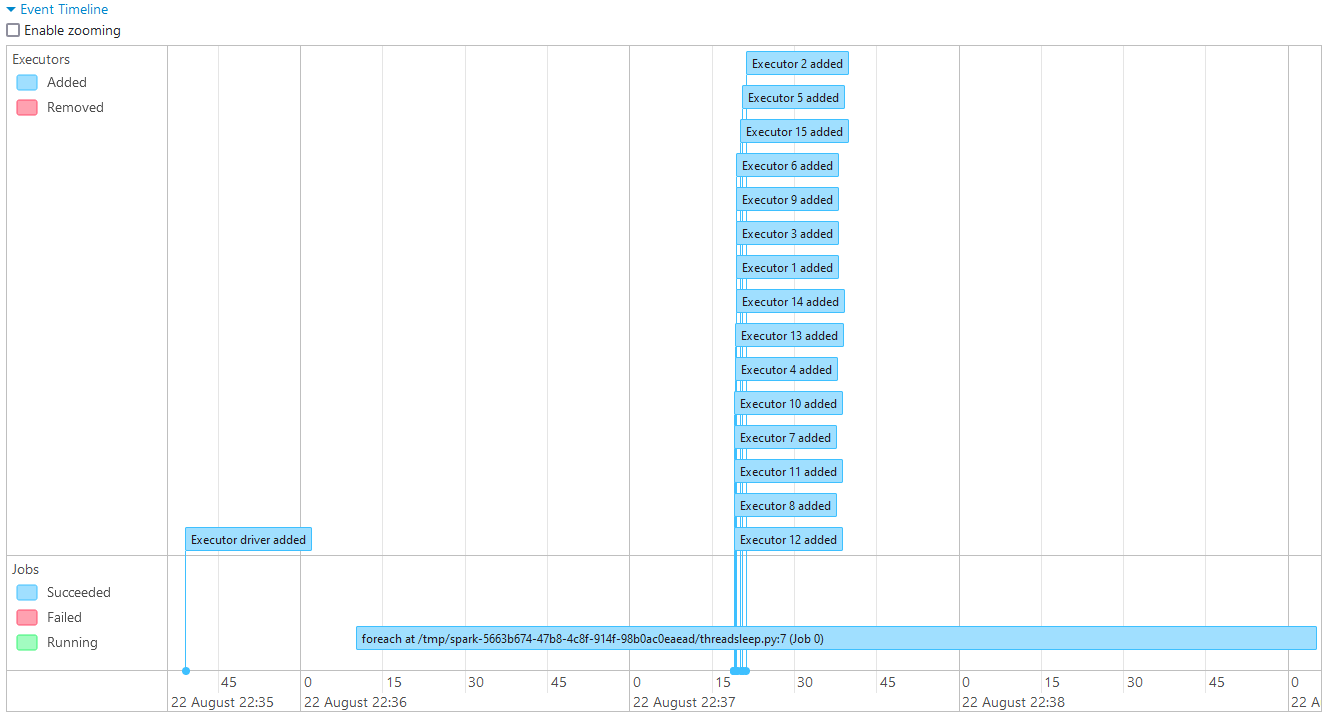
Below shows the event timeline of the Spark job. It adds all the 15 executors regardless of whether there are pending tasks or not. The DRA feature of Spark can be beneficial in this situation and it’ll be discussed in the next section.
With Dynamic Resource Allocation (DRA)
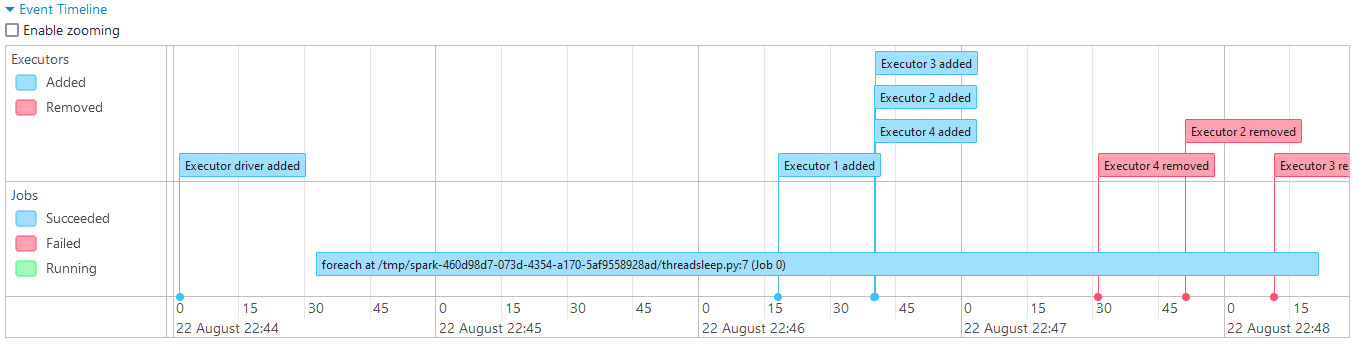
Here the initial number of executors is set to 1. With DRA enabled, the driver is expected to scale up the executors until it reaches the maximum number of executors if there are pending tasks.
export VIRTUAL_CLUSTER_ID=$(terraform –chdir=./infra output –raw emrcontainers_virtual_cluster_id) |
As expected, the executors are added dynamically and removed subsequently as they are not needed.
Summary
In this post, it is discussed how to provision and manage Spark jobs on EMR on EKS with Terraform. Amazon EKS Blueprints for Terraform is used for provisioning EKS, EMR virtual cluster and related resources. Also Karpenter is used to manage Spark job autoscaling and two Spark jobs with and without Dynamic Resource Allocation (DRA) are used for comparison. It is found that Karpenter manages transient nodes for Spark jobs to meet their scaling requirements effectively.



