After installing the AWS SCT on your platform of choice and restoring the AdventureWorks database onto a suitable SQL Server instance go ahead and open the SCT and create a new project as shown in Figure 1.
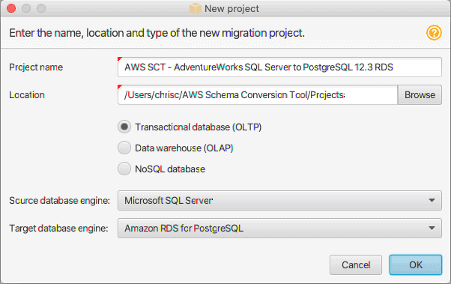
Enter the specific details of your project into the dialog as shown in Figure 2.
Connect to your source by clicking the “Connect to Microsoft SQL Server” toolbar button. Enter your source details and test the connection as shown in Figure 3.

Assuming the connection test was successful, click “OK”.
The source schema will now be displayed in a tree-view pane on the left hand side of the project screen as shown in Figure 4.

Using a suitable PostgreSQL instance – I’ve set one up in AWS using RDS running PostgreSQL version 12.3 – click on the “Connect to Amazon RDS for PostgreSQL” toolbar button to set up your target. Enter your target details and test the connection as shown in Figure 5.

Assuming the connection test was successful, click “OK”.
The target schema will now be displayed in a tree-view pane on the right hand side of the project screen as shown in Figure 6. There’s not a great deal to see here yet as we haven’t converted anything!
It’s probably a good idea at this point to save your project.
Go ahead and create your first conversion report by right clicking your mouse on the “AdventureWorks2017” node in the source tree-view and selecting “Create report” in the context sensitive menu as shown in Figure 7.

The conversion report is made up of three sections; the Executive Summary, Database Objects with Conversion Actions and Detailed Recommendations.
This section of the conversion report gives a visual representation of the conversion effort – “green is good”, “red is bad”!
Database storage objects and database code objects are represented by two histograms, with each object falling into one of the following four areas:

Those database conversions that can be achieved automatically can be applied to the target database either on an individual object basis or in bulk by selecting the appropriate level in the target database schema tree-view pane on the right hand side of the project screen as shown in Figure 8.




