MLflow is a widely used tool in the machine learning (ML) industry, valued for its ability to simplify complex ML projects while promoting collaborative development among practitioners. Its features make it an essential platform for managing the end-to-end machine learning lifecycle efficiently.

Machine Learning Lifecycle
Experimentation is at the heart of machine learning workflows, driven by the exploratory and iterative nature of model development and training. Below is a brief description of what a typical machine learning lifecycle looks like:
- Before model training begins, numerous preprocessing and feature engineering techniques can be applied to build a good model.
- The selection of an algorithm can feel overwhelming, as options range from statistical models and traditional machine learning models to deep learning models. The algorithm choice significantly impacts the model training results.
- Experimentation extends beyond algorithm selection; after an algorithm is chosen, the process is far from complete. Hyperparameter tuning – finding the optimal parameters for the setup – is necessary, as various combinations affect model performance.
- During model training, metrics must be tracked, as they provide critical information for later review. Understanding key aspects like training, validation and testing loss, as well as accuracy charts, becomes essential.
- After training is completed, additional elements such as model evaluation results and model registry details must be tracked to ensure reproducibility and auditability.
- Finally, once a model has been registered, we can now talk about model deployment. Model serving is a very important part of the process as this will be what the customer will eventually interact with, where its execution will directly impact customer satisfaction.
- And that is just the modelling side of things. We know that in Machine Learning, the dataset that we use for model training is just as important. For example, if your problem is in image classification, you can define your train, validation and test images and tag them as a dataset version that is immutable, making sure that you will have experiment reproducibility. Keeping track of what dataset was used in which experiment is always of utmost importance.
Introducing Amazon SageMaker with MLflow
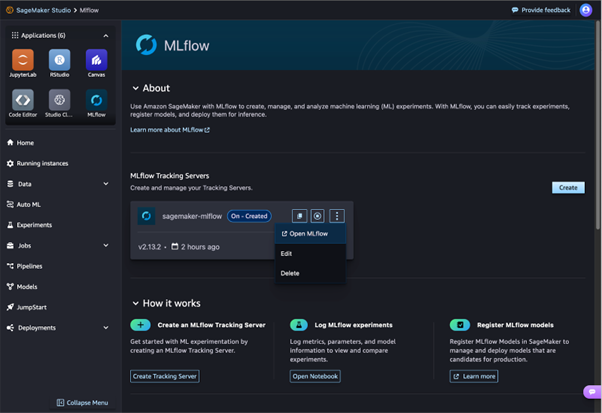
In June 2024, Amazon announced the general availability of Amazon SageMaker with MLflow, offering a fully managed version of the popular ML workflow management platform. This is a significant improvement, as many ML practitioners previously had to host MLflow manually using services like EC2 or Fargate.
While this was possible, it required managing permissions, networking, S3 buckets and a database – tasks that users had to maintain on their own. To give you an idea on what is involved in doing this yourself, here is a guide from AWS on how to setup an MLflow server on AWS Fargate.
Now, with a fully managed option, setting up and managing ML experimentation has become much simpler.
AWS Managed MLflow Service
An MLflow system has three main components – the Tracking Server, the Backend metadata store, and finally the artifact storage. All these components are securely hosted on Amazon.
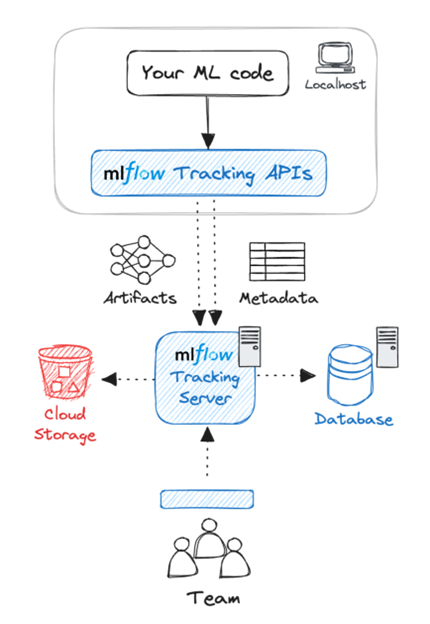
MLflow Tracking Server
An MLflow Tracking Server is a stand-alone HTTP server that provides the REST API service for interacting with the backend metadata store as well as the artifact store. When managing MLflow yourself, you would have several options when configuring your setup.
With the managed version in AWS SageMaker, these choices are all managed for you. Once your tracking server has started, you can then start monitoring your experiments efficiently. To interact with your Tracking Server, for example if automation is required, MLflow operations can be performed using AWS CLI or Boto3 interface.
MLflow backend metadata store
The backend store persists various metadata for each experiment run, such as run ID, start and end times, parameters and metrics to name a few. This ensures that all experiment metadata is comprehensively tracked and all experiments are managed efficiently.
MLflow artifact store
In addition to the many metadata generated with each training run, there are also many artifacts produced. Things like trained models, datasets, logs, and charts. Amazon S3 is the perfect repository to securely store all these artifacts.
Advantages of SageMaker with MLflow
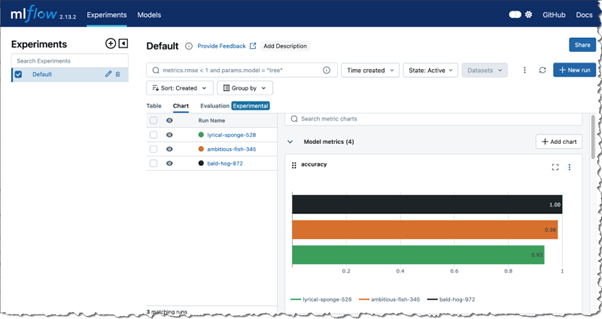
Comprehensive Experiment Tracking
There is a plethora of options to track experiments from – from Jupyter notebooks in local laptops, to various IDE’s such as VSCode, to managed IDE’s in SageMaker Studio. From within training or pre-processing jobs and finally from SageMaker Pipelines.
Full MLflow Capabilities
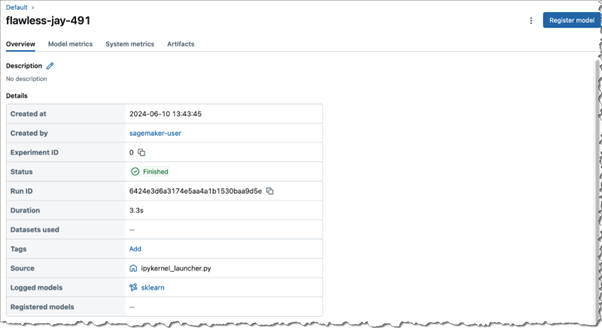
All the functionality that you have come to love in MLflow, such as Tracking, Evaluations and Model Registry, are available in this managed version.
Unified Model Governance
One feature that I like is the MLflow model registry, and because it is now integrated with SageMaker, whatever models you have registered in MLflow, will have been registered in AWS SageMaker too!
Efficient Server Management
As this is a managed version of MLflow, things like provisioning and upgrading are things that you do not have to worry about anymore. SageMaker takes care of scaling, patching and ongoing maintenance, without the customer managing any of the underlying infrastructure.
Enhanced Security
Using AWS Identity and Access Management (IAM), standard IAM policies can grant or deny access to MLflow APIs. It uses the same security features that are now familiar to AWS professionals.
Effective Monitoring and Governance
Control, monitoring and governance of your MLflow Tracking server is done using Amazon EventBridge and AWS CloudTrail. While EventBridge allows you to capture and be notified of key events like when experiments are created or models registered, Cloudtrail enables governance by recording detailed logs of user and API activities.
How to get started
To get yourself started with MLflow, including prerequisites and initial setup, please follow this guide from AWS.
Pricing
Amazon SageMaker with MLflow allows customers to pay only for what you use. Customers pay for MLflow Tracking Servers based on compute and storage costs.
Customers will pay for compute based on the size of the Tracking Server and the number of hours it was running. In addition, customers will pay for any metadata stored on the MLflow Tracking Server.
For example, using a Small Tracking server size costs $0.642 per hour while its storage will be $0.11 per GB per month. One feature that is handy to know is that this server can be easily turned off when not in use and turned on only when required. It is also an option to schedule when the tracking server is available, to avoid having to pay for the service when it is idle.
SageMaker with MLflow is generally available in all AWS Regions where SageMaker Studio is available, except China and US GovCloud Regions.
Please see the AWS Pricing page for more details, then find and click on the MLflow tab.
Conclusion
I had the chance to use SageMaker with MLflow in a recently concluded machine learning project. I have used it multiple times before this, and I remember that setting it up manually was not a big deal or trivial either. However, in this project, it was a non-event – just a few clicks and a short wait for the tracking server to be ready. It allowed me to focus on the job I had to do which was to build the best machine learning model that the project needed.
Since SageMaker with MLflow is a managed service that incurs charges even when the tracking server is idle, you can rest assured that you have the option to turn off the tracking server when it’s not in use. As the data is stored in a database and the artifacts are stored in S3 buckets, they will still be available once you restart the tracking server. Keep in mind that tracking server storage costs will still be incurred even when the server is idle.
With MLflow running, I no longer need to worry about tracking the results of all my experiments. MLflow takes care of this seamlessly for me and my team, allowing me to focus on the bigger picture. Since all experiment results are accessible at any time, it greatly enhances collaboration, accelerates the experimentation process, and boosts our confidence in the project’s progress.
Cevo Australia has expertise in building AI systems, ranging from traditional Machine Learning systems to Generative AI solutions for enterprises. For example, we have worked with an Australian manufacturer to build a design similarity search engine, contributing to time saving efficiencies and improved customer satisfaction. The system used Machine Learning experimentation in AWS SageMaker with MLflow, enabling reproducibility and auditability.

JO is a Machine Learning Engineer and his background is in Full Stack Software Development. He has expertise in the end-to-end Data Science Lifecycle from Machine Learning Systems to Generative AI solutions.
He has several years of experience in the development of mission-critical software for a broad range of industries spanning digital twins, industrial automation, biomedical engineering, manufacturing systems, banking, firmware, energy management and automotive retail.



