Apache Kafka is a popular distributed event store and stream processing platform. Previously loading data from Kafka into Redshift and Athena usually required Kafka connectors (e.g. Amazon Redshift Sink Connector and Amazon S3 Sink Connector). Recently these AWS services provide features to ingest data from Kafka directly, which facilitates a simpler architecture that achieves low-latency and high-speed ingestion of streaming data. In part 1 of the simplify streaming ingestion on AWS series, we discuss how to develop an end-to-end streaming ingestion solution using EventBridge, Lambda, MSK and Redshift Serverless on AWS.
Part 1 – MSK and Redshift (this post)
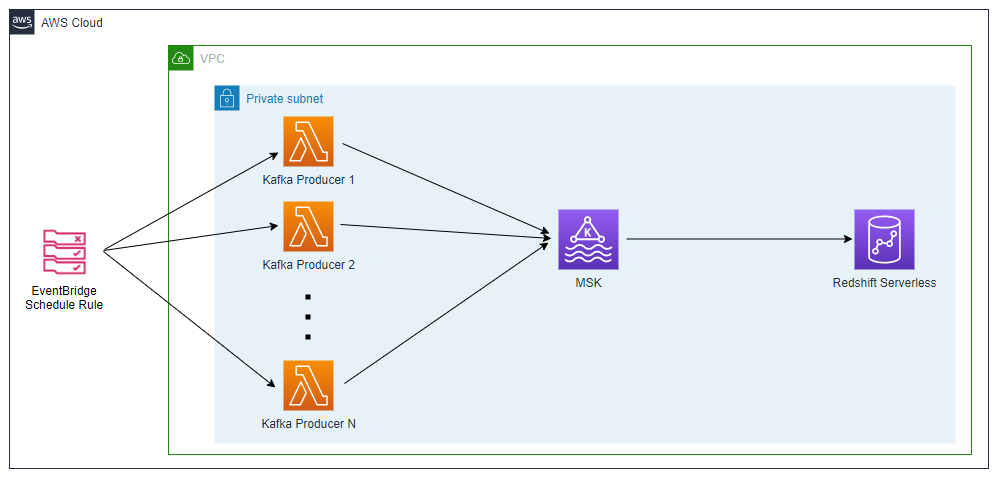
Architecture
Fake online order data is generated by multiple Lambda functions that are invoked by an EventBridge schedule rule. The schedule is set to run every minute and the associating rule has a configurable number (e.g. 5) of targets. Each target points to the same Kafka producer Lambda function. In this way we are able to generate test data using multiple Lambda functions according to the desired volume of messages. Once the messages are sent to a Kafka topic, they can be consumed by a materialized view in an external schema that sources data from the MKS cluster. The infrastructure is built by Terraform and the AWS SAM CLI is used to develop the producer Lambda function locally before deploying to AWS.
Infrastructure
A VPC with 3 public and private subnets is created using the AWS VPC Terraform module (vpc.tf). Also a SoftEther VPN server is deployed in order to access the resources in the private subnets from the developer machine (vpn.tf). It is particularly useful to monitor and manage the MSK cluster and Kafka topic as well as developing the Kafka producer Lambda function locally. The details about how to configure the VPN server can be found in an earlier post. The source can be found in the GitHub repository of this post.
MSK
A MSK cluster with 3 brokers is created. The broker nodes are deployed with the kafka.m5.large instance type in the private subnets. IAM authentication is used for the client authentication method. Note this method is the only secured authentication method supported by Redshift because the external schema supports either the no authentication or IAM authentication method only.
# integration-redshift/infra/variable.tf |
Inbound Rules for MSK Cluster
We need to allow access to the MSK cluster from multiple AWS resources. Specifically the VPN server needs access for monitoring/managing the cluster and topic as well as developing the producer Lambda function locally. Also the Lambda function and Redshift cluster need access for producing and consuming messages respectively. Only the port 9098 is added to the inbound/outbound rules because client access is enabled by the IAM authentication method exclusively. Note that the security group and outbound rule of the Lambda function are created here while the Lambda function is created in a different Terraform stack. This is for ease of adding it to the inbound rule of the MSK’s security group and later we will discuss how to make use of it with the Lambda function.
# integration-redshift/infra/msk.tf
|
Redshift Serverless
A namespace and workgroup are created to deploy a Redshift serverless cluster. As explained in the Redshift user guide, a namespace is a collection of database objects and users and a workgroup is a collection of compute resources.
# integration-redshift/infra/redshift.tf |
IAM Permission for MSK Access
As illustrated in the AWS documentation, we need an IAM policy that provides permission for communication with the Amazon MSK cluster. The applicable policy is added to the default IAM role of the cluster.
# integration-redshift/infra/redshift.tf resource “aws_iam_role” “redshift_serverless_role” { |
Kafka Producer
The resources related to the Kafka producer Lambda function are managed in a separate Terraform stack. This is because it is easier to build the relevant resources iteratively. Note the SAM CLI builds the whole Terraform stack even for a small change of code and it wouldn’t be convenient if the entire resources are managed in the same stack.
Producer Source
The Kafka producer is created to send messages to a topic named orders where fake order data is generated using the Faker package. The Order class generates one or more fake order records by the create method and an order record includes order id, order timestamp, user id and order items. The Lambda function sends 100 records at a time followed by sleeping for 1 second. It repeats until it reaches MAX_RUN_SEC (e.g. 60) environment variable value. A Kafka message is made up of an order id as the key and an order record as the value. Both the key and value are serialised as JSON. Note that the stable version of the kafka-python package does not support the IAM authentication method. Therefore we need to install the package from a forked repository as discussed in this GitHub issue.
# integration-redshift/kafka_producer/src/app.py import os |
A sample order record is shown below.
{ |
Lambda Function
As the VPC, subnets, Lambda security group and MSK cluster are created in the infra Terraform stack, they need to be obtained from the producer Lambda stack. It can be achieved using the Terraform data sources as shown below. Note that the private subnets can be filtered by a specific tag (Tier: Private), which is added while creating them.
# integration-redshift/infra/vpc.tf module “vpc” { … locals { … infra_prefix = “integration-redshift” … } |
The AWS Lambda Terraform module is used to create the producer Lambda function. Note that, in order to develop a Lambda function using AWS SAM, we need to create sam metadata resource, which provides the AWS SAM CLI with the information it needs to locate Lambda functions and layers, along with their source code, build dependencies, and build logic from within your Terraform project. It is created by default by the Terraform module, which is convenient. Also we need to give permission to the EventBridge rule to invoke the Lambda function and it is given by the aws_lambda_permission resource.
# integration-redshift/kafka_producer/variables.tf locals { # integration-redshift/kafka_producer/main.tf |
IAM Permission for MSK
The producer Lambda function needs permission to send messages to the orders topic of the MSK cluster. The following IAM policy is added to the Lambda function according to the AWS documentation.
# integration-redshift/kafka_producer/main.tf resource “aws_iam_policy” “msk_lambda_permission” { |
EventBridge Rule
The AWS EventBridge Terraform module is used to create the EventBridge schedule rule and targets. Note that 5 targets that point to the Kafka producer Lambda function are created so that it is invoked concurrently every minute.
# integration-redshift/kafka_producer/main.tf module “eventbridge” { |
Deployment
Topic Creation
We first need to create the Kafka topic and it is done using kafka-ui. The UI can be started using docker-compose with the following compose file. Note the VPN connection has to be established in order to access the cluster from the developer machine.
# integration-redshift/docker-compose.yml version: “3” |
A topic named orders is created that has 3 partitions and replication factors. Also it is set to retain data for 4 weeks.

Once created, it redirects to the overview section of the topic.

Local Testing with SAM
To simplify development, the Eventbridge permission is disabled by setting to_enable_trigger to false. Also it is shortened to loop before it gets stopped by reducing msx_run_sec to 10.
# integration-redshift/kafka_producer/variables.tf locals { … |
The Lambda function can be built with the SAM build command while specifying the hook name as terraform and enabling beta features. Once completed, it stores the build artifacts and template in the .aws-sam folder.
$ sam build –hook-name terraform –beta-features |
We can invoke the Lambda function locally using the SAM local invoke command. The Lambda function is invoked in a Docker container and the invocation logs are printed in the terminal as shown below.
$ sam local invoke –hook-name terraform module.kafka_producer_lambda.aws_lambda_function.this[0] –beta-features |
We can also check the messages using kafka-ui.

External Schema and Materialized View Creation
As we have messages in the orders topic, we can create a materialized view to consume data from it. First we need to create an external schema that sources data from the MSK cluster. We can use the default IAM role as we have already added the necessary IAM permission to it. Also we should specify the IAM authentication method as it is the only allowed method for the MSK cluster. The materialized view selects key Kafka configuration variables and parses the Kafka value as data. The JSON_PARSE function converts the JSON string into the SUPER type, which makes it easy to select individual attributes. Also it is configured to refresh automatically so that it ingests up-to-date data without manual refresh.
CREATE EXTERNAL SCHEMA msk_orders |
We can see the ingested Kafka messages as shown below.

Order Items View Creation
The materialized view keeps the entire order data in a single column and it is not easy to build queries for analytics. As mentioned earlier, we can easily select individual attributes from the data column but the issue is each record has an array of order items that has a variable length. Redshift doesn’t have a function to explode an array into rows but we can achieve it using a recursive CTE. Below shows a view that converts order items array into rows recursively.
CREATE OR REPLACE VIEW order_items AS |
We can see the exploded order items as shown below.

Kafka Producer Deployment
Now we can deploy the Kafka producer Lambda function and EventBridge scheduler using Terraform as usual after resetting the configuration variables. Once deployed, we can see that the scheduler rule has 5 targets of the same Lambda function.

We can check if the Kafka producer sends messages correctly using kafka-ui. After about 30 minutes, we see about 840,000 messages are created in the orders topic.

Query Order Items
As the materialized view is set to refresh automatically, we don’t have to refresh it manually. Using the order items view, we can query the top 10 popular products as shown below..

Summary
Streaming ingestion from Kafka (MSK) into Redshift and Athena can be much simpler as they now support direct integration. In part 1 of the simplify streaming ingestion on AWS series, we discussed an end-to-end streaming ingestion solution using EventBridge, Lambda, MSK and Redshift. We also used AWS SAM integrated with Terraform for developing a Lambda function locally.



