“Generative AI has captured our imaginations, this technology has reached its tipping point,” said Swami Sivasubramanian, vice president of Database, Analytics, and Machine Learning at Amazon Web Services (AWS).
Generative AI refers to a type of machine learning that focuses on creating new, original content rather than just analysing existing data or making predictions based on patterns. It utilises ultra-large models, such as large language models (LLMs), which are pre-trained on massive datasets. These models, often referred to as “foundation models” (FMs), have a deep understanding of language and can generate human-like text, images and even code.
Introduction
In this article, we will be exploring Langflow, AWS Bedrock and DataStax Astra Database and using this tech stack to create a simple RAG implementation.
Langflow
Langflow is an uncomplicated way to build from simple to complex AI applications. It is a low-code platform that allows you to integrate AI into everything you do. One of the key features of Langflow is its user-friendly APIs, which abstract away the complexities of NLP and allow developers to focus on building high-quality models. It supports a wide range of pre-trained language models, including state-of-the-art transformer architectures like BERT, GPT, and T5. These pre-trained models serve as powerful building blocks that can be fine-tuned on domain-specific data to achieve superior performance on a variety of NLP tasks.
Langflow – Create your chatbot!
AWS Bedrock
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customise them with your data using techniques such as fine-tuning and Retrieval Augmented
Generation (RAG) and build agents that execute tasks using your enterprise systems and data sources. Since Amazon Bedrock is serverless, you do not have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. This service is available now for the Sydney region.
Build Generative AI Applications with Foundation Models – Amazon Bedrock – AWS
DataStax Astra Database
Vector search is an innovative approach to searching and retrieving data that leverages the power of vector similarity calculations. Unlike traditional keyword-based search, which matches documents based on the occurrence of specific terms, vector search focuses on the semantic meaning and similarity of data points. By representing data as vectors in a high-dimensional space, vector search enables more accurate and intuitive search results.
And this is made available in DataStax Astra DB. We can build GenAI applications by using Astra DB as Vector store which enhances the capabilities of the LLM (Large Language Models) model in inferencing the information retrieved from the Vector Store.
Build GenAI application using Langflow, AWS Bedrock and Astra DB
Langflow is available as a python package and needs at least Python 3.10 version.
Installing and setting up Langflow Development Environment:
You can install Langflow with pipx or with pip. We need a tool to manage our Python environments. We will use Conda. Commands to configure conda environment are below:
mkdir –p ~/miniconda3 |
At this point we must re-initialise the terminal so type:
exit |
The terminal will close. Re-open it just like before. Now we will create a Python environment and then install Langflow.
conda create –name langflow python=3.10 |
Now, start Langflow app:
langflow run –host 0.0.0.0 |
Langflow app opens in a browser and displays a blank canvas where we can create projects.

Create a Project by choosing the suitable Flow.

Once the project is created, we can see the adapters on the left-hand side which we can drag and drop into the workspace to create a workflow.

Hello World App
Let us create a Simple chat App to demonstrate the easiness of using Langflow. Drag and drop Chat Input and Chat Output from left hand side to workspace and make a connection between two, as shown in screenshot. And once the connection is made, click the ‘Run’ button at the bottom left corner of the workspace.

This loads the app which we created just now, and we can chat with it as below.

But this is basic and let us make it interesting by introducing an LLM using AWS Bedrock.
Introducing AWS Bedrock Adapter
Remove the connection between that chat adapters, drag and drop AWS Bedrock Adapter in between and make connections as shown in the screenshot.

Notice that AWS Bedrock Adapter has quite a few options to choose the LLM, Profile name, Region etc. Once the Connections are established Click the Run button and now the chat application uses Anthropic Claude LLM before outputting the result.

Now let us make this more interesting by introducing DataStax Astra DB to store the information scrapped from Website.
Introducing Astra DB Adapter
Create a New blank project. Drag and drop the adapters as shown in the screenshot and make connections. We use URL adapter to scrape Web site and AWS Bedrock Embedding model to create Embeddings required for Vector Store. And finally, Astra DB to store these embeddings.
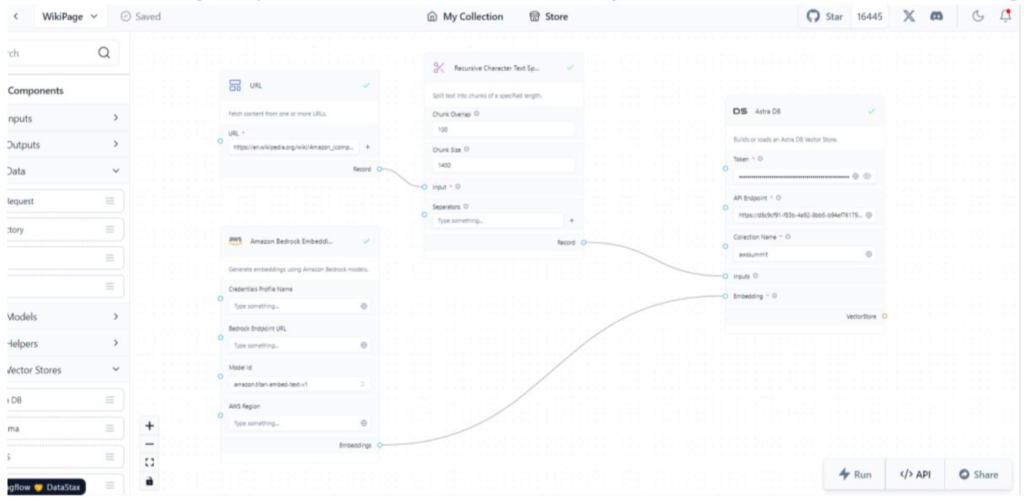
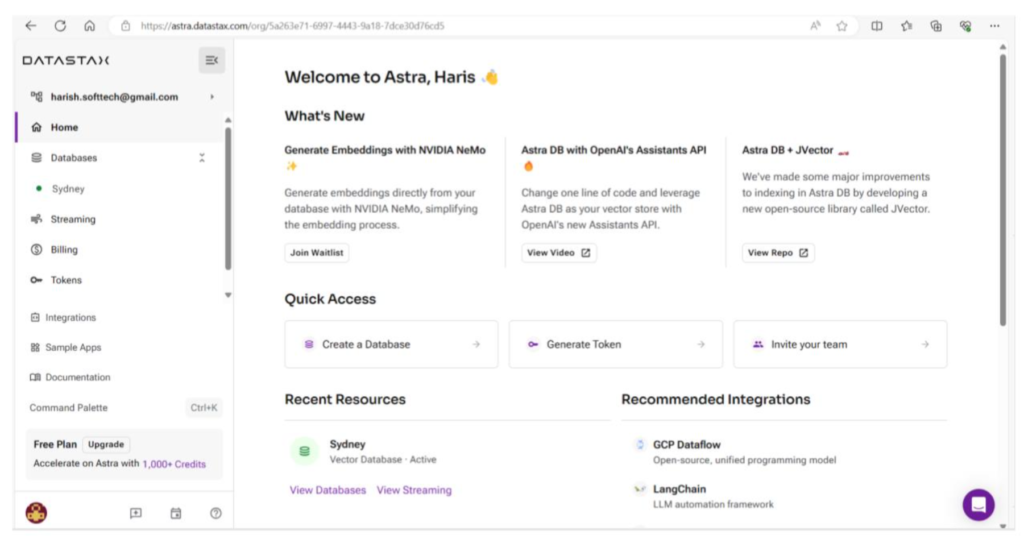
DB Adapter has quite a few options where we must define API, token, and collection name for the Astra DB. The below screenshot gives an idea of how Astra DB interface looks and creating token for your specific DB to use in the Langflow adapter.
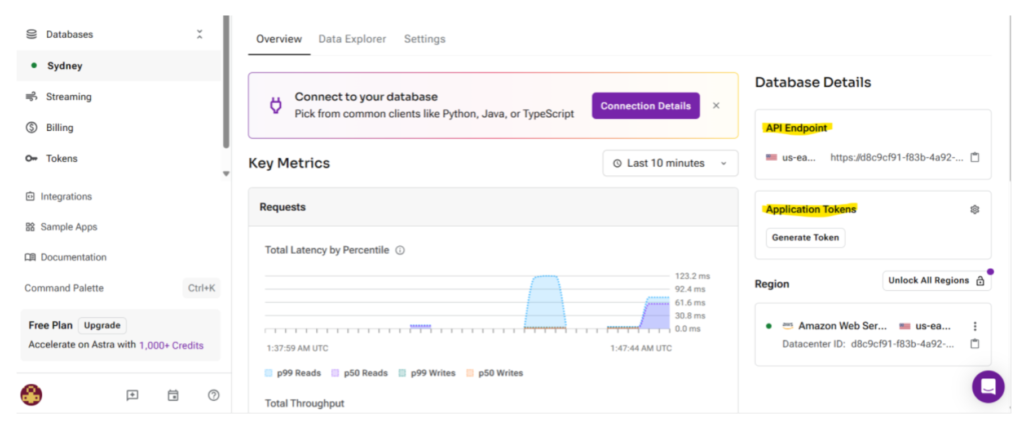
Once the DB adapter options are updated, click the ‘Run’ button at the bottom right-side of the screen and App starts scrapping website and storing the embedding in the Astra DB. We can see the database with records in Astra DB interface.

So this App will store the data provided into a Vector Database. And we now need a RAG implementation to make this complete Chat application where we can ask question on the data provided.
RAG Implementation
Lets make this more interesting by adding RAG implementation. Create a new project in Langflow by choosing ‘Vector Store RAG’ template.
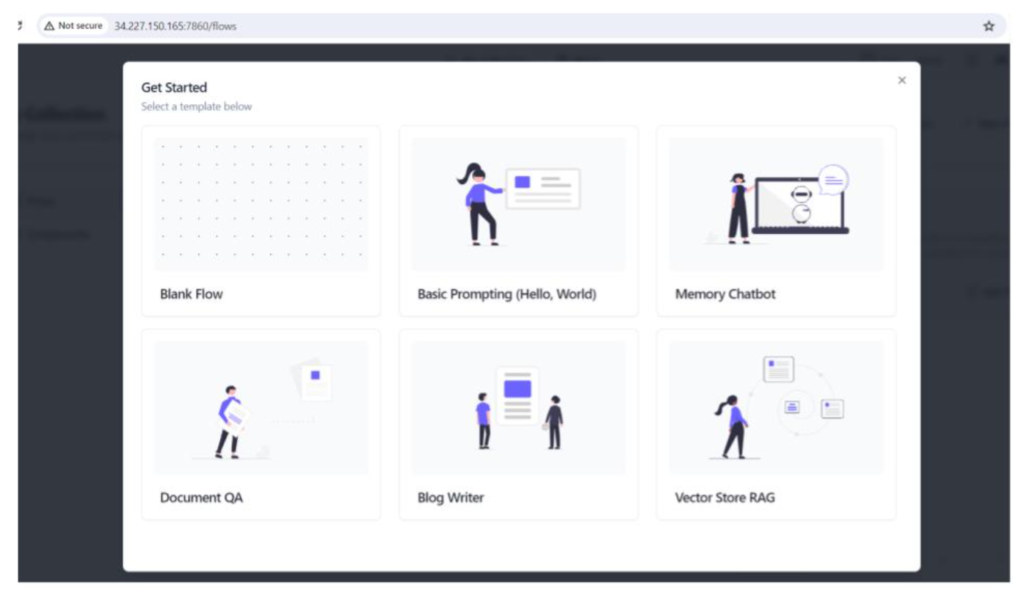
This will create a templateas shown in the below screenshot with the necessary connections. We can modify the respective Adapter options to suit our requirements.
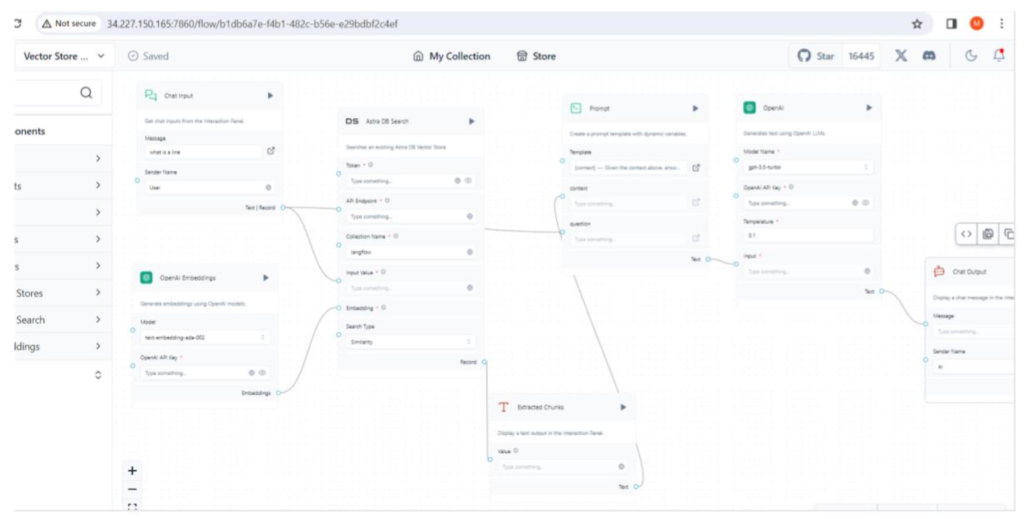
Notice that output from DB adapter is passed to ‘Prompt’ adapter which serves as imput to the ‘OpenAI’ LLM adapter and finally passed to ‘Chat Output’ Adapter. This demonstrates the easy usage of Langflow to create a GenAI application
Recap: Foundation Models
In the project we had gone through earlier we came across 2 different models, Large Language Models and Embedding Models. Both are Foundation Models.
Will briefly explain these models and key differences.
Large Language Models (LLMs) are a type of deep learning models trained on extensive datasets using attention mechanism to understand and generate text, images, videos etc. These models, such as OpenAI’s GPT and Google’s BERT, contain billions of parameters and can capture complex patterns in natural language. LLMs are commonly used for tasks like text generation, language translation, and sentiment analysis, with their performance often fine-tuned in specific domains.
Embedding Models are models that take any unstructured input and generate embeddings. In natural language processing (NLP), embeddings are generated from large text corpora using techniques like Word2Vec and GloVe. These embeddings provide dense numerical representations of words, which are used as input features for various NLP tasks, including text classification, named entity recognition, and machine translation.
The key differences between Large Language Models and Embedding Models lie in their size, complexity, and usage. Both models complement each other. Unlike LLMs, embedded models do not generate language output but focus on representing text data in a compact, meaningful way.
Conclusion
In summary, AWS Bedrock made it easy for us to implement LLMs and Langflow is an easy-to-use LLM Framework to implement AI applications with low code. Astra DB from DataStax can be easily integrated into GenAI applications and with its vector search capabilities it makes LLM usage efficient.
Up Next
As we had explored usage of Langflow, AWS Bedrock and Astra DB, the next blog will explore the end-to end solution of RAG implementation and will demonstrate the real time working of the App



