And today we’re back with part 2 of our Introduction to AWS CloudFormation where we’ll be taking a look at CloudFormation templates. As we learnt in part one, CloudFormation templates are where we define the desired state of our workloads. In this article, we will take a look at:
- The overall structure of a CloudFormation Template
- How we define resources we want in our solution
- The benefits of outputting the end state of our resources
- How to add Variability to our Templates through the use of Parameters
- Walk through the process of writing a template
By the end of this article you should be able to write your own AWS CloudFormation templates, understand how to add flexibility through the use of parameters and output the final state of the deployed resources for consumption by other templates. In future articles we will take a look at some of the more advanced features Templates have to offer.
The components of a CloudFormation template
As outlined in the introductory article, CloudFormation templates can be written in either JSON or YAML. For the purposes of this article we will be focused on writing our CloudFormation templates in the YAML. The main reason for this is that YAML is easier for humans to read and follow visually. For information on the JSON equivalent you can refer to the AWS CloudFormation User guide available here.
CloudFormation templates are broken up into ten(10) major sections. Taken from the official CloudFormation documentation, they are:
- Format Version (optional) The AWS CloudFormation template version that the template conforms to. The template format version isn’t the same as the API or WSDL version. The template format version can change independently of the API and WSDL versions.
- Description (optional) A text string that describes the template. This section must always follow the template format version section.
- Metadata (optional) Objects that provide additional information about the template.
- Parameters (optional) Values to pass to your template at runtime (when you create or update a stack). You can refer to parameters from the Resources and Outputs sections of the template.
- Rules (optional) Validates a parameter or a combination of parameters passed to a template during a stack creation or stack update.
- Mappings (optional) A mapping of keys and associated values that you can use to specify conditional parameter values, similar to a lookup table. You can match a key to a corresponding value by using the Fn::FindInMap intrinsic function in the Resources and Outputs sections.
- Conditions (optional) Conditions that control whether certain resources are created or whether certain resource properties are assigned a value during stack creation or update. For example, you could conditionally create a resource that depends on whether the stack is for a production or test environment.
- Transform (optional) For server less applications (also referred to as Lambda-based applications), specifies the version of the AWS Server less Application Model (AWS SAM) to use. When you specify a transform, you can use AWS SAM syntax to declare resources in your template. The model defines the syntax that you can use and how it’s processed. You can also use AWS::Include transforms to work with template snippets that are stored separately from the main AWS CloudFormation template. You can store your snippet files in an Amazon S3 bucket and then reuse the functions across multiple templates.
- Resources (required) Specifies the stack resources and their properties, such as an Amazon Elastic Compute Cloud instance or an Amazon Simple Storage Service bucket. You can refer to resources in the Resources and Outputs sections of the template.
- Outputs (optional) Describes the values that are returned whenever you view your stack’s properties. For example, you can declare an output for an S3 bucket name and then call the aws cloudformation describe-stacks AWS CLI command to view the name.
Which ultimately means that for a CloudFormation template to be valid, all we need is a Resources section. Other sections can be added in order to provide additional functionality where required.
Getting Started with our first template
ok, let’s set the scene… Let’s say we need a new S3 bucket to host files that will be generated by our new application. We don’t want it to be publicly available and we’d like versioning enabled :
How would we write a CloudFormation template to address the above? well, as we learnt from the previous section… All we need is a Resources Section, so let’s start with that.
Resources:
But that’s not going to do much, so the next step would be to define the S3 bucket we need. A neat thing to know is that AWS has every available resource documented in the user guide for us to reference. If we take a look under Amazon S3 we can find the documentation on how to declare an S3 Bucket. As we can see from the screenshot below, there are a lot of potential properties we can define.
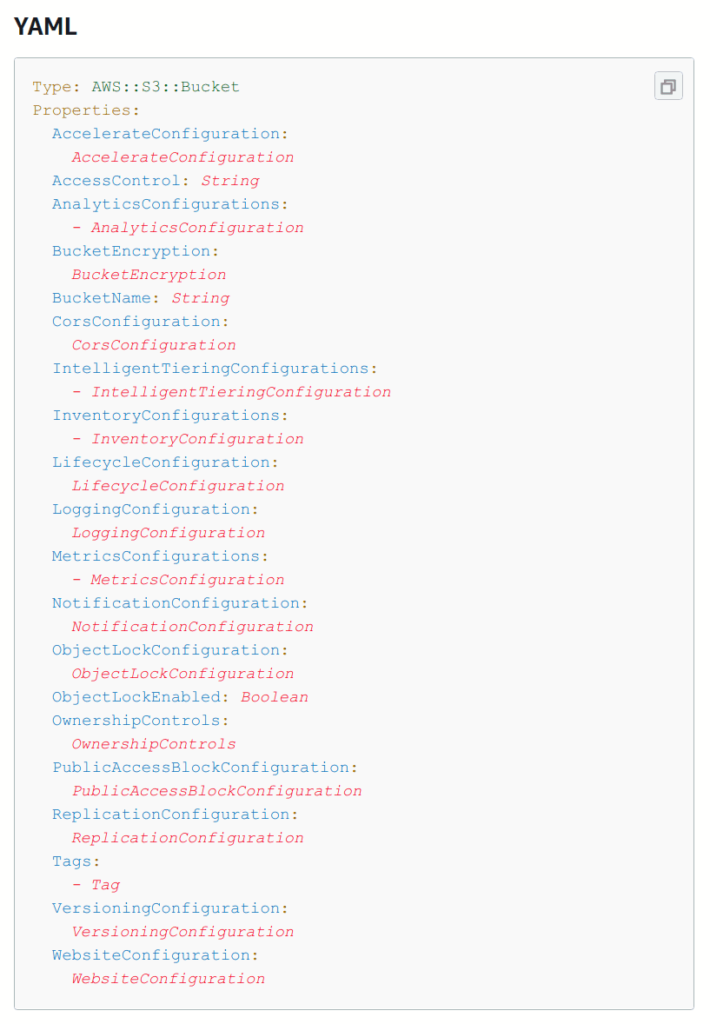
Reading through the documentation we can see that none of the defined properties are actually required to deploy an S3 bucket. So how do we declare our S3 bucket in our CloudFormation bucket? we’ll there are 2 steps:
1. We first need to declare a logical name for our new resource under the resources section of our template as shown below:
Resources:
MyFirstS3Bucket:
2. Next we need to define what type of resource MyFirstS3Bucket is going to be. This is shown in the above properties screenshot to be AWS::S3::Bucket
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
and that’s it… If you took that template and deployed a stack from it, you’d have a brand new S3 Bucket. Because we didn’t define anything it uses default values and given it a pseudo random name… but it’s deployed and available. I say Pseudo random because it will use the stack name and logical resource name as part of the name.
So how do we enabled versioning on the bucket?
To define and configure properties, we just need to declare them as outlined in the documentation. Taking a look at the documentation we can see the VersioningConfiguration Property will enable what we want:

We can see it needs a VersioningConfiguration Type declared, and we can see more about how to declare that by clicking on the link:

We can see that the VersioningConfiguration type requires a single property Status declared. The Status value will allow either Enabled or Suspended as valid values.
Putting all that together we can then add the required properties to our existing resource
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: Enabled
How do we make this a little more reusable?
Say we want multiple S3 Buckets, some with versioning enabled and some with it simply Suspended… how could we do that?
The answer is by utilising one of the other Sections available in CloudFormation templates, Parameters.
AWS Allows for a multitude of different Parameter types (strings, numbers, lists, etc.) but we will focus on Strings for today. In my next article we’ll dive deeper into how we can use different parameter types to simplify Stack deployments.
We can again take a look at the User Guide to see how we can define a parameter here. Much like a resource we need to define ** a logical name**, DataType and any required Properties.

So, knowing this we can update our template to request a parameter from our user which will define if the versioning is enabled or suspended.
Parameters:
Versioning:
Type: String
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: Enabled
Next, we want to leverage the value of the parameter in our resource. We can do this by leveraging an Intrinsic function of CloudFormation called Ref. Ref simply allows us to refer to another object within the template as shown below
Parameters:
Versioning:
Type: String
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: !Ref Versioning
Now, whatever is defined by the user as the value for Versioning will be passed through as a property on the S3 Bucket. But this does leave us open to one pretty major problem. What if the user makes a mistake and types the wrong value?
We can address this by defining what values are allowed for our Parameter. If we take a look at the Documentation again, we can see we can define the AllowedValue property

Taking this into account we can add it to our Versioning parameter and come up with the below:
Parameters:
Versioning:
Type: String
AllowedValues:
- Enabled
- Suspended
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: !Ref Versioning
When we try to deploy it into a stack, the user is now presented with a drop down list of possible options.

But how do I know what the name of the bucket is?
We can now deploy S3 buckets and select if we want versioning enabled or not… But the Buckets names are random. How can we know what the bucket is called and use it elsewhere in our project? The Answer is by leveraging the Outputs section of CloudFormation Templates.
Outputs give us an easy way to publish the values/configuration settings of our newly deployed resources. These values can then be referenced by other templates, code or AWS services to understand how things have been deployed. How to achieve and manage this will be the subject for a future article. But for now we’ll focus on outputting the bucket’s name so it can be referenced.
We start (unsurprisingly by now I’m sure) with the CloudFormation User Guide on Outputs.

We won’t worry about Export for the moment (we’ll pick that up in a future article) and will for now focus on the Logical ID and the Value.
Parameters:
Versioning:
Type: String
AllowedValues:
- Enabled
- Suspended
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: !Ref Versioning
Outputs:
BucketName:
Value: ???
So where do we get our Value from, from the documentation on S3 Bucket Return Values. Every CloudFormation resource has a set of values it can return back. These can be Names, ARN’s, URl and connection strings (among others). For S3 buckets, we are interested in the bucket name which we can get by using our old friend Ref.

Parameters:
Versioning:
Type: String
AllowedValues:
- Enabled
- Suspended
Resources:
MyFirstS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: !Ref Versioning
Outputs:
BucketName:
Value: !Ref MyFirstS3Bucket
And there we have a complete CloudFormation Template that deploys an S3 Bucket and returns its name. If we go ahead and deploy this as a Stack we can see our Bucket’s name in the outputs section:

Conclusion
And that’s how it’s done. By leveraging the CloudFormation Documentation we can piece together our Template piece by piece. In my next article I will continue the journey through CloudFormation by taking a look at how and when we might want to leverage multiple Templates to form a single workload. If there is anything specific you’d like covered as a part of this series on CloudFormation please feel free to reach out.



