The Business Problem
All machine learning solutions begin as business problems that need to be addressed. For example, in the wake of COVID-19, there is heightened awareness for issues and challenges within the healthcare and medical industries.
One such persistent global challenge is malaria. In 2022, malaria claimed the lives of 249 million people. Despite common misconceptions, malaria remains a significant problem in many regions around the world.
A more effective and scalable method of diagnosis could help eradicate malaria. Currently, diagnosing malaria is a manual and labor-intensive process that involves using a microscope to count infected red blood cells on a slide, requiring skilled technicians. Given the prevalence of the disease in poorer countries, finding a better diagnostic method is crucial.
In this use case, machine learning can significantly enhance the diagnostic process, ensuring a faster, more accurate and more affordable method.
Machine Learning is an iterative process
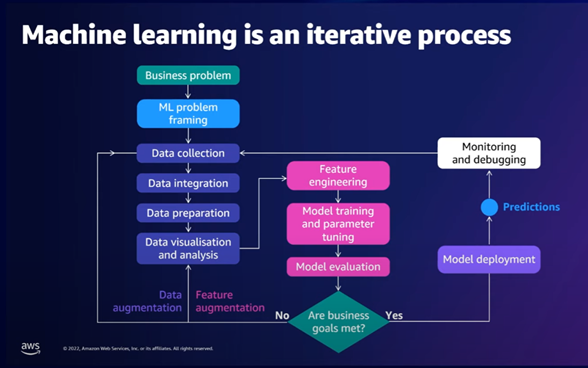
Once it is identified that machine learning can aid in solving this business problem, data collection and sourcing are initiated by the data scientist. Typically, this data requires extensive preprocessing and feature engineering to make it suitable for modeling. After features are prepared, model building can commence.
An extensive body of work exists for image classification in similar use cases, which can be leveraged for malaria diagnosis. This may include using pre-trained image models, fine-tuning them, or developing custom deep learning models from scratch.
Following model building, model evaluation is conducted to ensure that the model generalises well to unseen, real-world data. This cycle of building and evaluation continues until the business objectives are met. Deployment of the model into a production environment is then essential, with various options available for model serving.
Once deployed, the system’s predictions are monitored to detect any performance degradation due to data drift or other factors. If retraining is required, all steps are repeated until the business goals are met.
Given the complexity and number of steps involved, Machine Learning Operations (MLOps) principles and tools like SageMaker Pipelines are valuable for orchestrating and automating these processes efficiently.
Introducing SageMaker Pipelines for MLOps
Amazon SageMaker Pipelines is a fully managed service that automates and orchestrates machine learning workflows. It is designed to help data scientists and machine learning engineers streamline the processes of building, training and deploying machine learning models. SageMaker Pipelines integrates seamlessly with other AWS services, providing a robust and scalable environment for MLOps. Whether the machine learning problem is image classification, as in our malaria diagnosis use case, or any other ML task, SageMaker Pipelines facilitates efficient MLOps for your project.
Key Features of SageMaker Pipelines
- Pipeline Creation – SageMaker Pipelines allow you to define and manage end-to-end machine learning workflows.
- Automation – It allows you to automate repetitive tasks and string them together to produce a workflow that you can run from start to finish.
- Scalability – Workflows have different needs so one can configure tasks to use whatever compute and how many you need. After the workflow completes its job, all the compute get shut down until they are needed again.
- Integration – SageMaker Pipelines can integrate with all the AWS Services, such as S3, Lambda and SageMaker with MLflow to provide a compete MLOps package.
- Monitoring and Logging – While SageMaker does not have this functionality built-in, creating monitoring and logging through CloudWatch metrics, or even better with MLflow ensures that you can monitor your training pipeline as well as your predictions. SageMaker with MLFlow is also another AWS managed service that works together with SageMaker Pipelines.
Benefits of the MLOps process
- Reproducibility – Ensures that machine learning workflows are reproducible by maintaining a consistent environment and versioning of data, code and models.
- Collaboration – Facilitates collaboration among data scientists, engineers, and other stakeholders by providing a centralised platform for managing ML workflows.
- Efficiency – Reduces the time and effort required to move models from development to production by automating key steps in the ML lifecycle.
- Scalability – Handles large-scale machine learning tasks efficiently, allowing you to focus on model development (which is where the value lies) rather than infrastructure management.
- Compliance – Helps in maintaining compliance with organisational and regulatory requirements by providing audit trails and version control.
Using SageMaker Pipelines
Since its introduction in re:Invent 2020, Amazon SageMaker has continued to deliver the ability to provide best-in-class DevOps practices in machine learning projects. There are a couple of different ways to use SageMaker Pipelines in your projects – through the classical SageMaker Pipelines and the newer @step decorator method.
Types of Steps
- ProcessingStep – Used for data preprocessing and postprocessing tasks.
- TrainingStep – Used for model training tasks.
- TransformStep – Used for batch transform jobs.
- ModelStep – Used for registering models in the SageMaker Model Registry.
- ConditionStep – Used for conditional branching in the pipeline.
- CallbackStep – Used to integrate external systems into the pipeline.
- LambdaStep – Used to invoke AWS Lambda functions.
Amazon curates numerous examples of using the Python SDK to build MLOps pipelines in Github – from your vanilla workflows to more advanced examples, even those that involve generative AI.
Classical SageMaker Pipelines
Simply put, SageMaker pipelines are a collection of steps, and these steps are stringed together in workflows called pipelines.
Steps: Fundamental units of work in a SageMaker Pipeline, such as data processing, model training, and model evaluation.
Pipelines: A sequence of steps that are executed in a specific order to automate machine learning workflows. To create a workflow, you would need to pass the step’s properties or the outputs of one step as the input to another step in the pipeline.
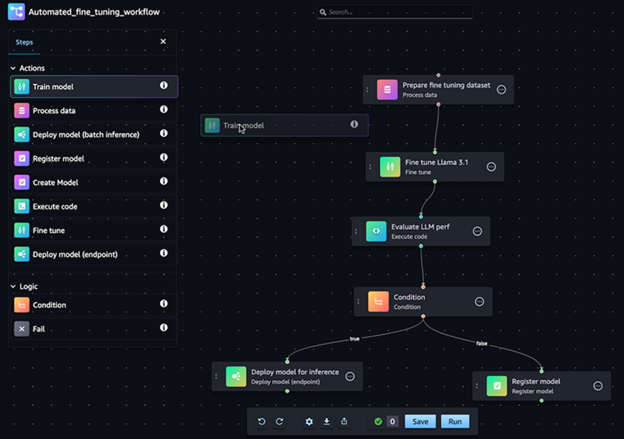
Using SageMaker Studio visual interface
If you are more after a visual, low-code, drag-and-drop interface, then one can build SageMaker pipelines using the Pipeline Designer in SageMaker Studio. With this method, there is no need to know Python, as all you need to do is drag and drop your way to build your pipeline, then this generated pipeline can then be exported to JSON.
Using SageMaker Python SDK
If your preference is writing Python code to define your pipelines, then use the SageMaker Python SDK to build your pipeline. Amazon have a lot of Python code examples of building SageMaker Pipelines using the Python SDK.
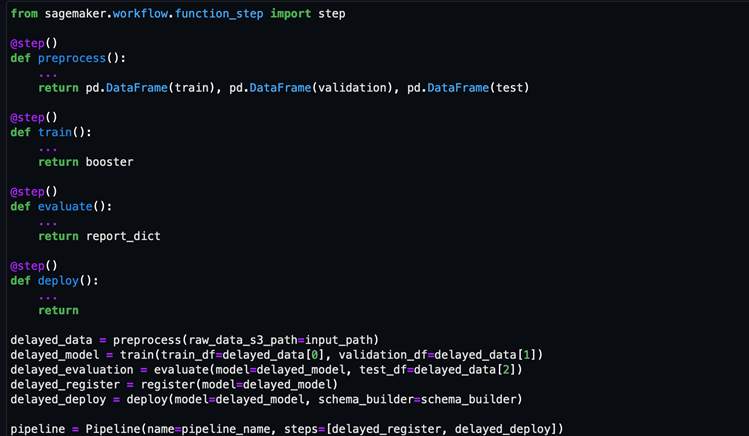
The Step Decorator
On November 2023, a new functionality was added to SageMaker Pipelines to simplify the developer experience for building pipelines. A new Python decorator was added – the @step decorator can be used for custom steps. This allows one to convert your Python ML code into SageMaker pipeline Training Jobs that can run on AWS. Most of the functionality of the classical SageMaker Pipelines are there, however, there are some limitations as defined here.
This feature provides ML practitioners the capability of moving your ML workflows to AWS with minimal code changes, providing you a lift-and-shift experience of moving your ML code running in your local machine up to the AWS cloud.
Conclusion
To summarise, SageMaker Pipelines offers an invaluable framework for managing the MLOps workflow involved in machine learning projects, from data preparation to model deployment and monitoring.
In the case of the malaria diagnosis use case, where timely and accurate identification of parasitised cells is critical, SageMaker Pipelines ensures that each step – from data ingestion and feature engineering to model training, evaluation, and deployment – runs seamlessly and efficiently.
By automating these processes, data scientists can focus more on refining the model and less on technical infrastructure challenges, accelerating the deployment of robust diagnostic tools that support critical healthcare initiatives in the real world.
Cevo Australia specialises in building AI solutions, encompassing both traditional Machine Learning systems and Generative AI solutions for enterprises in many domains. For instance, we collaborated with an Australian manufacturer to develop a design similarity search engine, which resulted in significant time savings and enhanced customer satisfaction. This system leveraged MLOps principles, as outlined in this article, and was built around Amazon SageMaker Pipelines to ensure robustness, scalability and reproducibility.

JO is a Machine Learning Engineer and his background is in Full Stack Software Development. He has expertise in the end-to-end Data Science Lifecycle from Machine Learning Systems to Generative AI solutions.
He has several years of experience in the development of mission-critical software for a broad range of industries spanning digital twins, industrial automation, biomedical engineering, manufacturing systems, banking, firmware, energy management and automotive retail.



