TL;DR
Data engineering is evolving from manual ETL scripting to delivering robust, production-grade data products. By adopting DevOps principles on the Databricks Lakehouse Platform—modular code, rigorous automated testing, CI/CD pipelines with Git Folders, and Databricks Asset Bundles, teams can automate deployment, ensure reliability, and accelerate delivery. This approach transforms data work into scalable, maintainable, and production-ready data solutions.
Table of Contents
Introduction
The role of the Data Engineer has fundamentally shifted. It is no longer enough to write functional ETL (Extract, Transform, Load) scripts; modern data delivery requires building robust, scalable, and secure data products. This transformation mandates the adoption of DevOps principles, a powerful convergence of culture, automation, and tooling applied directly to the Databricks Lakehouse Platform, a modern approach compared to other data architectures.
By integrating software engineering best practises, rigorous testing, and automated Continuous Integration and Continuous Delivery (CI/CD), organisations can transition from manual, error-prone data workflows to automated, production-grade pipelines, but first, it’s important to ensure a solid data strategy is in place. In this blog I explore the essential components needed to achieve true DataOps maturity and master DevOps for Data Engineering on Databricks.
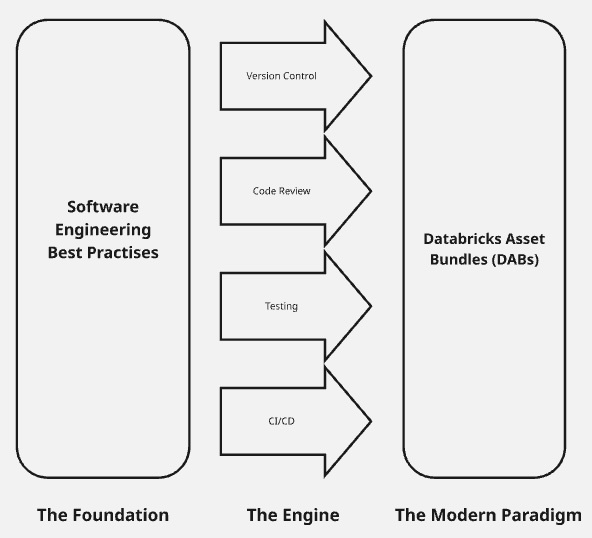
1. The Foundation: Software Engineering Best Practices (SWE)
The foundation of any successful DevOps strategy is high-quality code. Before automation can be effective, the assets being automated must be reliable and maintainable. This requires every Data Engineer to adopt the mindset of a Software Engineer.
Modular Design and Code Quality
The first step away from “notebook scripting” is embracing modularity. Rather than writing sprawling, single-purpose notebooks, your logic should be decomposed:
- Reusable Components: Core data transformation logic (e.g., standardising addresses or calculating metrics) must be factored out into reusable Python or Scala modules. These modules should be stored outside the notebook environment, versioned separately, and imported when needed. This practise ensures your logic is DRY (Don’t Repeat Yourself).
- Style and Readability: Adherence to standards, formats, and consistent naming conventions is essential. Automation tools should run during the development cycle to ensure code is consistently formatted and easy for any team member to read and debug.
- Documentation: Documentation moves beyond simple comments. Every function and class should include detailed docstrings explaining its purpose, parameters, and return values. This intrinsic documentation significantly lowers the barrier to entry for new developers and simplifies maintenance.
Rigorous Automated Testing
The only way to guarantee a pipeline works reliably is through automated testing. Testing provides the confidence required to implement Continuous Delivery safely.
- Unit Testing: This is the most granular level of testing. Unit tests should verify individual functions and modules without needing a live Spark session or access to Databricks. This ensures the core business logic remains sound, irrespective of the underlying data platform.
- Integration Testing: This is where the Databricks environment becomes critical. Integration tests check how different parts of the pipeline interact, for instance, loading data from an external source, applying Spark transformations, and writing the result to a Delta Lake table. These tests ensure the end-to-end data flow works as expected within the target environment.
- Data Quality Check: Beyond code functionality, testing in data engineering requires validating the data itself. Features within Delta Live Tables (DLT) like Expectations are a powerful form of testing, allowing engineers to define data quality rules that can warn, quarantine, or fail a pipeline if constraints are violated.
Best Practise Tip: Always write your unit tests before or while writing the actual transformation code (Test-Driven Development). If you find a bug in production, write a test that reproduces it before fixing the bug.

2. DevOps for Data Engineering on Databricks: Building CI/CD Pipelines
Implementing DevOps for Data Engineering on Databricks provides the framework for how we deliver this high-quality code continuously. In the data world, this is often called DataOps, and applying these principles ensures pipelines evolve safely and predictably as data changes over time.
Continuous Integration (CI)
CI is the foundation of modern delivery. It is a development practise where developers merge code changes frequently (at least once a day) into a shared central repository to enforce code quality.
The CI process, typically executed by an automation server (e.g., GitHub, GitLab), performs several critical, automated checks:
- Build Validation: Checking out the code and ensuring all library dependencies resolve correctly.
- Linting and Formatting: Enforcing code quality standards and style.
- Unit Test Execution: Running all unit tests on the code modules.
- Security Scanning: Checking for dependencies with known vulnerabilities.
For Databricks, CI ensures that every committed change has passed all software checks before it can even be considered a viable candidate for deployment.

Continuous Delivery (CD)
CD extends CI by automatically preparing and deploying the validated code to staging or testing environments. The core principle of CD is deployable artefacts: the jobs, libraries, and notebooks that passed CI are packaged and ready to be deployed to any downstream environment at a moment’s notice.
CD transforms data engineering delivery from a slow, manual ticketing process into an automated, low-risk release cadence.
See Databricks references on CI/CD

3. Continuous Integration in Databricks: Leveraging Git Folders
The biggest obstacle for CI in Databricks used to be synchronising the external Git repository with the internal notebook environment. Databricks Git Folders (or Repos) solved this problem, making CI a seamless reality.
Git Folders as the Workspace Bridge
Git Folders connect a specific folder in a Databricks workspace directly to a remote Git repository (e.g., Azure DevOps, GitHub). This integration achieves several crucial objectives:
- Enforced Source of Truth: The remote Git repo, not the Databricks workspace, becomes the authoritative source of your code. If the workspace is accidentally deleted, your code persists safely in Git.
- Branch-Based Development: Developers can check out a specific feature branch within the Git Folder, develop and test their changes, and then use standard Git operations (commit, push, pull) to manage their work, all without leaving the Databricks UI.
- CI Triggering: When a developer pushes a change or opens a Pull Request (PR), the external Git service automatically triggers the CI pipeline. This pipeline fetches the new code, runs tests, and validates quality. Only after the PR is merged into the main branch does the code become a validated artefact, ready for CD.
See Databricks reference on Git Folders
4. The Path to CD: Databricks Deployment Methods
Once the code is validated in the CI phase, the final step is Continuous Deployment. This involves promoting the verified assets (jobs, DLT pipelines, models) from the version control system into the target Databricks workspace (Staging or Production).
Traditional Automation Interfaces
For many years, automation relied on the programmatic interfaces provided by Databricks:
- REST API and CLI: The Databricks REST API is the underlying engine for all automation. The CLI provides a convenient shell wrapper to execute API calls (e.g., uploading notebooks, creating clusters, configuring jobs). These tools are versatile but often require complex scripting to manage environment-specific variables and asset dependencies.
- Databricks SDKs: Available in languages like Python, these SDKs offer a cleaner, object-oriented way to interact with the Databricks control plane. They allow engineers to manage resources directly within their automation code.
The Modern Paradigm: Databricks Asset Bundles (DABs)
Databricks Asset Bundles (DABs) represent the current best practise for deploying complex solutions. They introduce Infrastructure-as-Code (IaC) principles to the Databricks environment.
A DAB is essentially a declarative YAML configuration file that defines all the resources required for an application or pipeline.
DAB Component | Description |
Artifacts | Specifies source notebooks and libraries to be deployed. |
Resources | Defines the operational assets: Databricks Jobs, Delta Live Tables (DLT) Pipelines, and Clusters. |
Environments | Allows easy switching between configuration parameters for different deployment targets (e.g., Staging vs. Production), handling variations in cluster size, secrets, and data paths. |
The Key Benefits of Databricks Asset Bundles (DABs):
- Atomic Deployment: DABs ensure that related assets—a job, its cluster, its pipeline, and its configuration—are deployed and managed as a single unit, eliminating configuration drift.
- Simplicity of CD: A single CLI command (Databricks bundle deploy) can handle the entire deployment process to a specified environment, drastically simplifying external CD pipeline scripts.
- Cross-Domain Support: DABs are versatile, used for deploying traditional Data Engineering pipelines, MLOps stacks, and any other solution composed of Databricks assets.
See Databricks reference on DAB
Conclusion: Embracing Engineering Excellence
Adopting DevOps for Data Engineering on Databricks is a journey that moves the organisation closer to true business agility. It’s a necessary shift from viewing data work as individual tasks to seeing it as a cohesive, software-driven product line and mastering DevOps for Data Engineering on Databricks ensures that transformation is sustainable, scalable, and future-ready.
By mandating modular code, enforcing automated testing, building CI/CD pipelines with Git Folders, and utilising the declarative power of Databricks Asset Bundles, Data Engineers can achieve unparalleled levels of pipeline reliability, consistency, and speed. This solidifies their role as critical enablers of the modern data-driven solution.
Key Takeaways
Key Takeaway | Why It Matters |
Software Engineering Best Practises | The code must be modular, tested, and documented before deployment can be reliable. |
DevOps & CI/CD | The engine that automates quality checks and deployment, making releases faster and safer. |
Databricks Git Folders | The bridge that connects code repository (Git) directly to the Databricks workspace, enabling Continuous Integration (CI). |
Databricks Asset Bundles (DABs) | The modern, declarative way to package and deploy everything—jobs, clusters, and pipelines—as a single, consistent unit across environments. |
The Result | A move from manual scripting to fully automated, production-grade data product delivery. |
What Next?
Ready to start your DevOps journey on Databricks?
- Start Small: Choose one existing notebook and refactor its core logic into a reusable Python module. Write a unit test for that module.
- Connect Git: Set up your first Databricks Git Folder, linking your workspace to a remote repository.
- Explore DABs: Experiment with creating a simple Databricks Asset Bundle to deploy a basic job.
Take that first step today and transform your data engineering workflow from reactive scripting to proactive engineering excellence.

Juzel is a Principal Data and Analytics Engineer with over 22 years experience in Data analysis, design and development of end to end Data solutions, and most recently for Modern Data Platforms like Databricks with a demonstrated history working in the non-for-profit, insurance, banking sector, manufacturing and IT Consultancy.



