TL;DR:
dbt Core and the dbt Platform use the same transformation engine, but differ significantly in how they are deployed, governed, and operated, making the right choice dependent on organisational maturity rather than technical capability.
Table of Contents
Introduction
As cloud data platforms mature, many organisations are adopting architectures where data is loaded first and transformed directly within the warehouse, rather than relying on external ETL engines. dbt fits naturally into this shift by providing a structured, SQL‑based framework for managing analytics transformations.
When teams adopt dbt, one of the earliest decisions is whether to use dbt Core, the open‑source command‑line framework, or the dbt Platform, a managed service that adds operational and collaboration capabilities. While both use the same transformation engine, they differ in how they are deployed, governed, and operated.
This blog compares dbt Core and the dbt Platform in the context of modern cloud data transformation, covering where dbt fits in the data stack, how each option is typically run, and the types of teams and environments where each approach is most effective.
dbt in the context of Modern Analytics Platform
As cloud data platforms mature, organisations are increasingly adopting ELT architectures where data is loaded first and transformed directly within the warehouse rather than through external ETL engines. This approach leverages the scalability, performance, and security of modern warehouses such as Snowflake, BigQuery, and Databricks, and has driven broad adoption of warehouse‑native transformation patterns (see dbt’s official case studies and customer list).
Within this architecture, dbt operates in the transformation layer. While the warehouse executes the SQL, dbt provides the structure required to manage transformation logic at scale, ensuring that raw data can be reliably shaped into analytics‑ready datasets.
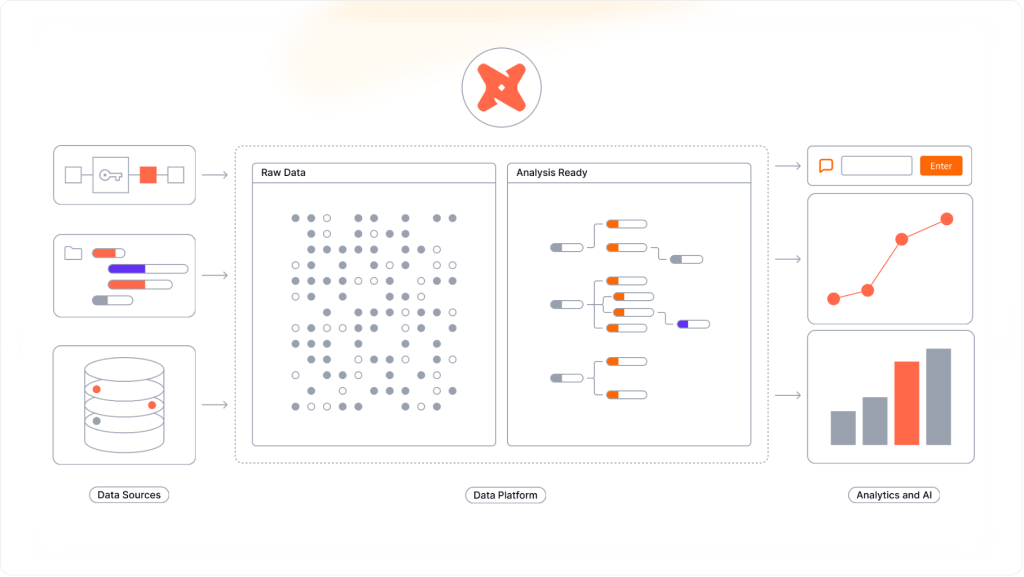
Specifically, dbt enables teams to:
- Define explicit dependencies between models using a directed acyclic graph (DAG)
- Execute transformations natively inside the warehouse, leveraging its compute and security
- Apply automated tests (e.g. not‑null, uniqueness, relationships) to validate data quality
- Generate documentation and lineage directly from transformation metadata
- Adopt software engineering practices such as modular code, version control, code review, and CI/CD for analytics workloads
dbt works alongside, rather than replacing, other tools in the data platform ecosystem:

- Ingestion tools load raw data into the warehouse
- The warehouse stores and processes raw and transformed data
- dbt performs in‑platform transformation, modelling, and testing
- Downstream BI, ML, and AI tools consume curated, analytics‑ready models
In this way, dbt acts as the connective layer between upstream ingestion and downstream consumption, helping teams operate from a consistent, well‑governed analytics foundation.
Running dbt with dbt Core
dbt Core is the open-source, command-line distribution of dbt. It is typically used as a developer-driven framework, where teams install dbt locally, write models in their preferred editor, and execute dbt commands via the CLI.
In organisations using dbt Core, dbt is usually integrated into an existing engineering ecosystem rather than operated as a standalone service. Execution is commonly triggered through external schedulers or orchestration tools, and CI workflows are implemented using the organisation’s standard automation platforms, and—in secure or tightly governed environments dbt Core is sometimes run as an on‑demand, containerised workload.
Visit this On‑Demand dbt Execution blog for more detailed discussion.
dbt Core provides the transformation engine itself — compiling SQL models, managing dependencies, and executing transformations inside the data warehouse. Everything surrounding that engine is implemented and maintained by the team, including:
- Job scheduling and orchestration
- Secrets and credentials management
- Environment separation and deployment conventions
- CI workflows and validation checks
- Documentation hosting and operational monitoring
As a result, dbt Core is often embedded into broader platform or data engineering workflows, giving teams full control over how dbt is executed, deployed, and observed.
What Is the dbt Platform?

The dbt Platform is a hosted environment designed to manage dbt projects at scale. It provides a central place to develop, test, schedule, document, and observe dbt runs, with built‑in support for CI/CD, environment management, and team collaboration.
Importantly, the dbt Platform does not change how data is transformed—that remains the responsibility of dbt Core. Instead, it changes how dbt is adopted, operated, and governed as it becomes a shared, production‑critical capability across teams.
Key Capabilities of the dbt Platform
The dbt Platform adds managed capabilities around execution, collaboration, and observability, including:
|
Capability |
Simple Explanation |
|
Browser‑based development environments |
A web‑based IDE (Studio IDE) that allows teams to develop, test, and run dbt models without installing dbt locally. |
|
Managed job scheduling and execution |
Built‑in scheduling and execution of dbt runs, supporting time‑based schedules and API or webhook triggers. |
|
Integrated CI for analytics engineering |
Native CI that automatically runs dbt builds and tests on pull requests using temporary schemas. |
|
First‑class environment management |
Explicit support for separate development, staging, and production environments. |
|
Hosted documentation and lineage |
Automatic generation and hosting of dbt documentation and lineage with access control. |
|
Run history, monitoring, and alerts |
Visibility into past runs, execution timings, and configurable success or failure notifications. |
|
Native Git integrations |
Built‑in integration with GitHub, GitLab, and Azure DevOps to support standard branching and pull‑request workflows. |
These capabilities significantly reduce the operational effort required to run dbt reliably in production, particularly in organisations where analytics engineering spans multiple teams or includes non‑engineering contributors.
Choosing Between dbt Core and the dbt Platform
Teams typically move from dbt Core to the dbt Platform for operational reasons rather than functional gaps. The underlying transformation logic remains the same; the difference lies in how dbt is deployed, governed, and operated as it becomes a shared, production‑critical capability across teams.
At a high level, dbt Core offers maximum flexibility and control but requires teams to build and maintain supporting infrastructure. The dbt Platform reduces this operational overhead by providing managed capabilities for execution, environments, CI/CD, documentation, and observability.
Operational Fit: dbt Core vs dbt Platform
Consideration | dbt Core | dbt Platform |
Team size & structure | Small, engineering‑led teams | Multiple teams contributing to models |
Operational maturity | Strong in‑house DevOps and platform capability | Limited appetite to build and maintain infrastructure |
CI/CD & execution | Custom CI, orchestration, and monitoring | Built‑in CI, managed scheduling, run history |
Environment management | Scripted or convention‑based | First‑class dev, staging, and prod |
Governance & access | Team‑managed | Centralised governance and access control |
Documentation & lineage | Generated and hosted internally | Automatically hosted and broadly accessible |
Control vs convenience | Full control prioritised | Consistency and ease of operation prioritised |
In practice, many teams start with dbt Core and adopt the dbt Platform as onboarding friction increases, CI/CD becomes harder to manage, or operational risk grows. The choice should be treated as an architectural decision, guided by team structure, governance needs, and long‑term maintainability rather than by transformation features alone.
Final Thoughts: Making dbt an Architectural Capability
dbt has become a cornerstone of modern data transformation because it brings engineering discipline to analytics workflows — modular code, testing, documentation, versioning, and reproducibility. Whether you choose dbt Core or the dbt Platform depends on how you want to operate that transformation layer.
In our consulting engagements, we see the dbt Platform become most valuable when transformation is a shared responsibility across teams and when operational reliability is a requirement rather than an aspiration. Conversely, dbt Core remains a strong option when teams already maintain mature platform capabilities or want maximum control.
Our recommendation is to treat this as an architectural decision, not a tooling decision. Evaluate it based on team structure, governance needs, operational maturity, and long-term maintainability.
What’s Coming Next
In my next blog – Modern Data Transformation with dbt – Part 2 : How to Structure Your dbt Project for Scale – I’ll explore practical patterns for modelling, naming conventions, folder structures, and development workflows that help teams collaborate effectively and avoid common pitfalls as their dbt projects grow.
Future posts in this series will also cover:
- Tests, documentation, and lineage in depth,
- CI/CD workflows tailored for analytics engineering,
- Orchestration patterns with Airflow, Dagster, and other tools,
- Common anti-patterns and how to avoid them.
Explore more of our blogs, where we share practical perspectives on analytics engineering, data platforms, cloud architecture, and secure execution models for modern enterprises.

Kiran is a Data Engineer with experience in designing and building Cloud Data applications and ETL pipelines for cloud data migration and building Enterprise Data Warehouses. Proven success in designing and optimising data pipelines to support business goals, and expertise in using a variety of data engineering tools and technologies.



