Over the last few months, new advancements in the field of ML/AI have transformed many aspects of our society. At the forefront of this development are powerful machine learning algorithms known as Foundation Models. Consequently, we are starting to see many organisations across multiple industries shifting their focus to building AI-based applications.
Traditional databases like relational databases (RDBMS) have served us well for a long time, but they have limitations when it comes to handling unstructured data (e.g. text). Language Models, specifically Large Language Models (LLMs) like GPT-4 (by OpenAI), LLaMa (by Meta) or Bard (by Google) are being used to draw insights from massive data sets. They are introducing a change in basic assumptions about how we store, manage, and retrieve data. The need for efficient handling of that kind of data is causing a significant push towards vector databases, a type of NoSQL database designed to handle large and complex data types effectively.
In this blog, we will answer the following questions:
- What is a vector database?
- How does a vector database work?
- How does vector database compare to traditional NoSQL database?
- What are the benefits of using a vector database?
- Which options are available on the market?
What is a vector database?
Embeddings
Before we define what is a vector database, we must understand what an embedding is. In the world of vector search, an embedding is a mathematical representation of data object (text, image, audio, video, etc.) generated by machine learning models (such as Large Language Models) as points in an embedding space. Each number represents different dimensions of the data that is essential for understanding patterns, relationships and underlying structures.
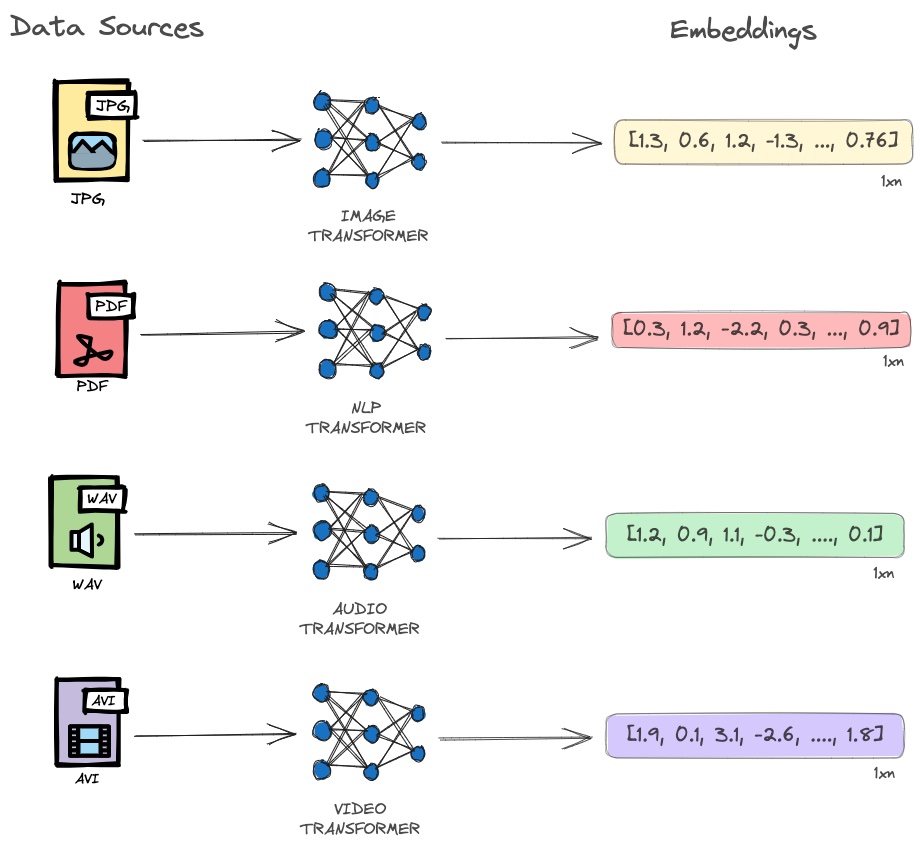
Vector embeddings are an incredibly versatile tool and can be applied in many domains.
Vector similarity
Now that we understand what embeddings are, we need to take a look at some of the ways we can conduct vector indexing as well as search.
Vector similarity is a way to find related objects that have similar characteristics using semantic relationships between objects. There are several algorithms used to find similarity between embeddings in a vector database, with the most popular being Cosine Similarity which measures the similarity using the cosine of the angle between two embeddings to quantify how similar two entities are (e.g. documents, images, etc.).

Many other search algorithms have made it to mainstream and provide faster search operation across all the embeddings stored in your vector database, just to name a few:
- ANN (Approximate Nearest Neighbour): an algorithm that uses distance algorithms to locate nearby vectors.
- FAISS (Facebook AI Similarity Search): Facebook’s similarity search algorithm.
- HNSW (Hierarchical Navigable Small World): a multilayered graph approach for determining similarity.
It is worth mentioning that the speed at which a search algorithm performs is a function of the choice in the indexing strategy. Embedding indexes are simply data structures we assign to our vectors.
Although we might still be able to build powerful LLM (Large Language Models) apps using vector search algorithms as they are, however, they present some key limitations:
- No backup.
- No storing of metadata along with the embeddings.
- No management of the embedding functions.
- No scalability.
- No real-time update.
- No security and access control.
That is why we need specialised databases designed specifically for handling this type of data and support for the limitations mentioned above.
Vector database
A vector database indexes and stores vector embeddings for fast retrieval and similarity search. It has full CRUD (Create, Read, Update and Delete) support that solves many of the limitations of pure vector search and is well-suited for enterprise-level production deployment.
Here is an image to highlight the difference between OLTP, OLAP and vector DBs.

How does a vector database work?
In traditional databases, queries typically involve finding rows where the value exactly matches the query. However, vector databases utilise a similarity metric to locate the vector most similar to the query.
Vector databases are able to retrieve similar objects of a query quickly because they use Approximate Nearest Neighbor (ANN) search, which uses different algorithms for indexing and calculating similarities. These algorithms enhance the search process through techniques such as hashing, quantisation, or graph-based search.
These algorithms are combined into a pipeline that enables rapid and accurate retrieval of the closest vectors based on a given query. As the vector database provides approximate results, there is a trade-off between accuracy and speed. Higher accuracy leads to slower queries, but an effective system can achieve ultra-fast search while maintaining near-perfect accuracy.
Here is a common pipeline for a vector database:

- The vector DB indexes vectors hence mapping the vectors to a data structure that will enable faster searching.
- The vector DB compares the indexed query vector to the indexed vectors in the database to find the nearest set of vectors by applying a similarity search algorithm.
- The vector DB retrieves the final nearest neighbour from the database and processes them to return the results.
How does vector database compare to traditional NoSQL database?
As data professionals navigate the ever-evolving landscape of data storage and retrieval, it becomes crucial to grasp the fundamental differences that set vector databases apart from their NoSQL counterparts (e.g. MongoDB). When comparing vector databases to traditional NoSQL DBs, we have identified four key differentiating factors:
- Data Representation: In traditional NoSQL databases, data is typically stored as key-value pairs, documents, or wide-column structures. In contrast, vector databases store and operate on vectors, which are mathematical representations of data points.
- Querying Approach: Traditional NoSQL databases often rely on exact matching queries based on keys or specific attribute values. Vector databases, on the other hand, use similarity-based queries, where the goal is to find vectors that are most similar to a given query vector.
- Optimisation Techniques: Vector databases employ specialised algorithms for Approximate Nearest Neighbor (ANN) search, which optimise the search process. These algorithms may involve techniques such as hashing, quantisation, or graph-based search. Traditional NoSQL databases typically focus on different optimisation methods depending on their data models.
- Use Cases: NoSQL databases are commonly used for a wide range of applications, such as content management, real-time analytics, and distributed systems. Vector databases, specifically designed for working with vectors, are often utilised in applications involving similarity matching, recommendation systems, image recognition, natural language processing, and other tasks that require vector-based operations.
These differences make vector databases particularly suitable for applications that require efficient similarity-based search and analysis of vector data, while traditional NoSQL databases are more versatile for general-purpose data storage and retrieval needs.
What are the benefits of using a vector database?
The rise of generative AI (Artificial Intelligence), exemplified by models like ChatGPT, introduces new possibilities for generating text and managing complex human conversations. Some models support multiple modalities, allowing users to describe a scene and generate a corresponding image. Despite their capabilities, generative models are susceptible to generating false information, leading to potential user deception. Vector databases can serve as external knowledge bases for generative AI chatbots, ensuring the delivery of reliable information.
Vector databases enable the practical use of embedding models, enhancing application development by providing essential features such as resource management, security controls, scalability, fault tolerance, and efficient information retrieval with advanced query languages. Other machine learning models can be used to automate metadata extraction from content like images and scanned documents. By indexing metadata alongside vectors, hybrid search combining keywords and vectors becomes possible. Furthermore, semantic understanding can be integrated into relevancy ranking, improving search outcomes.
A good vector database provides applications through features like:
- data management,
- fault tolerance,
- critical security features,
- query engine.
These capabilities allow users to operationalise their workloads to simplify scaling, maintain high scalability, and support security requirements. When considering building LLM applications, a typical reference architecture would include a few key elements which are illustrated in the diagram below:
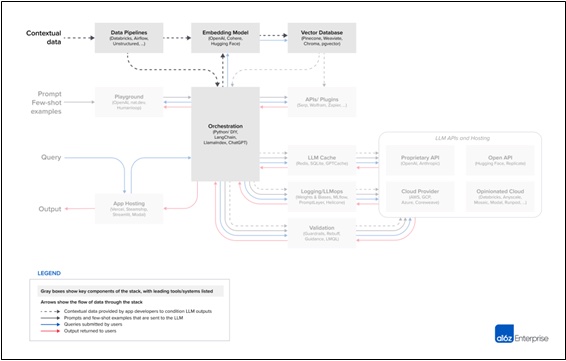
Which options are available on the market?
Since the democratisation of Large Language Models, we have seen a rise of the number of vector databases available on the market. Some of the more established vendors have added vector capabilities to their existing database offerings, whereas the newcomers are opting for a fully optimised cloud-based offering.
Vector Databases | Open Source | Developed in | Embedding mgmt. | SQL-like filtering | Full text search |
Chroma | Y | Python & Typescript | Y | Y | N |
Pinecone | N | N/A | N | Y | N |
Vespa | Y | Java & C++ | Y | Y | Y |
Milvus | Y | Golang & Python | N | Y | N |
Weaviate | Y | Assembly, C++, Golang | Y | Y | Y |
Qdrant | Y | Rust | Y | Y | Y |
When considering the right vector database that fits your use case, there are a few criteria we recommend for your operationalisation:
- Managed vs Self-Hosted: do you have own engineering team to look after self-hosting a vector database?
- Performance: what latency requirements does your app have? Is it served online or in batch offline mode?
- MLOps (Machine Learning Ops) Expertise: Does your team have experience managing ML (Machine Language) pipelines in production?
- Developer experience: Availability of API (Application Programming Interface) docs, ability to customise components of the vector database, error handling, tech support.
- Reliability: what is the uptime SLA (Service Level Agreement) you find in the managed or self-hosted vector database?
- Security: Is your vector database compliant with current standards specifying how organisations should manage customer data?
- Cost: how expensive is the cost of a self-hosting/managed vector database?
Closing Notes
There is no doubt LLM applications are a hot topic at the moment across multiple industries. They have a profound impact on the way we design software since the internet. They make it possible for individual developers to build incredible AI apps, in a matter of days, that surpass supervised machine learning projects that took months to build; and vector databases are key in giving life to these AI systems.
In this blog post, we explored what vector databases are and in the next one we will be looking into building a light LLM application on AWS (Amazon Web Services) …. Stay tuned!!!!



