In today’s data-driven world, the ability to efficiently manage and query vast amounts of embeddings is crucial. Whether you’re developing recommendation systems, natural language processing models, or image recognition algorithms, having a powerful vector database at your disposal is a game-changer. When it comes to deploying such a database, the cloud infrastructure offered by Amazon Web Services (AWS) stands as a reliable and scalable choice.
In this blog post, we will explore the deployment of an open-source vector database on AWS, optimised for handling embeddings. We will leverage a set of AWS services, including Virtual Private Cloud (VPC), Amazon EC2 instances, Amazon API Gateway, a Load Balancer, and Docker containers, to create a robust, highly available and secured architecture for our vector database.
The beauty of open-source solutions lies in their flexibility, affordability, and active community support. Our vector database of choice for this adventure is a powerful open-source option, renowned for its prowess in managing embeddings efficiently. By deploying it on AWS, we not only harness the strengths of the open-source ecosystem but also gain access to the elasticity and scalability that AWS is renowned for.
Whether you’re a developer, a DevOps enthusiast, or simply an AWS fan, this guide will provide you with the step-by-step instructions and insights needed to deploy a Chroma database on AWS sitting within a private VPC, designed to handle vector embeddings.
By the end of this article, you’ll have a fully functional vector database ready to power your machine-learning models and unlock the potential of embeddings in your GenAI applications. You might be asking yourself “Why do I need a vector database right now?” and it’s probably because you missed the article “Exploring The Power of Vector Databases” by my colleague Rene Essomba, so do yourself a favour and go read his excellent blog post.
Anyway, there are some scenarios where adding an API Gateway between internal resources makes a lot of sense, especially when the features provided by this service could improve the service reliability such as:
- Adding an SSL/TLS security layer in front of services that don’t provide this feature
- Limit the number of requests from misbehaving clients to avoid overloading the backend service through usage plans with API keys
- Secure resource access through IAM Policies and conditions
- Monitor the requests using Cloudwatch metrics and alarms
It’s important to keep in mind that API Gateway is one of the AWS services that doesn’t require a VPC to be deployed, running independently of any customer network setup in the cloud. This is nice when you have a fully cloud-native architecture based on serverless services, but will add a few steps to be deployed in a controlled, private environment.
In this article, I will show how I created the code to secure a Chroma Database service behind an API Gateway in a private subnet with all the required endpoints, VPC links and integrations, using the Cloud Development Kit library for Python to deliver a fully Infrastructure-as-code solution that can be quickly deployed and expanded.
Designing the API Gateway solution
Here we have a high-level design of the solution environment we will develop in this article:
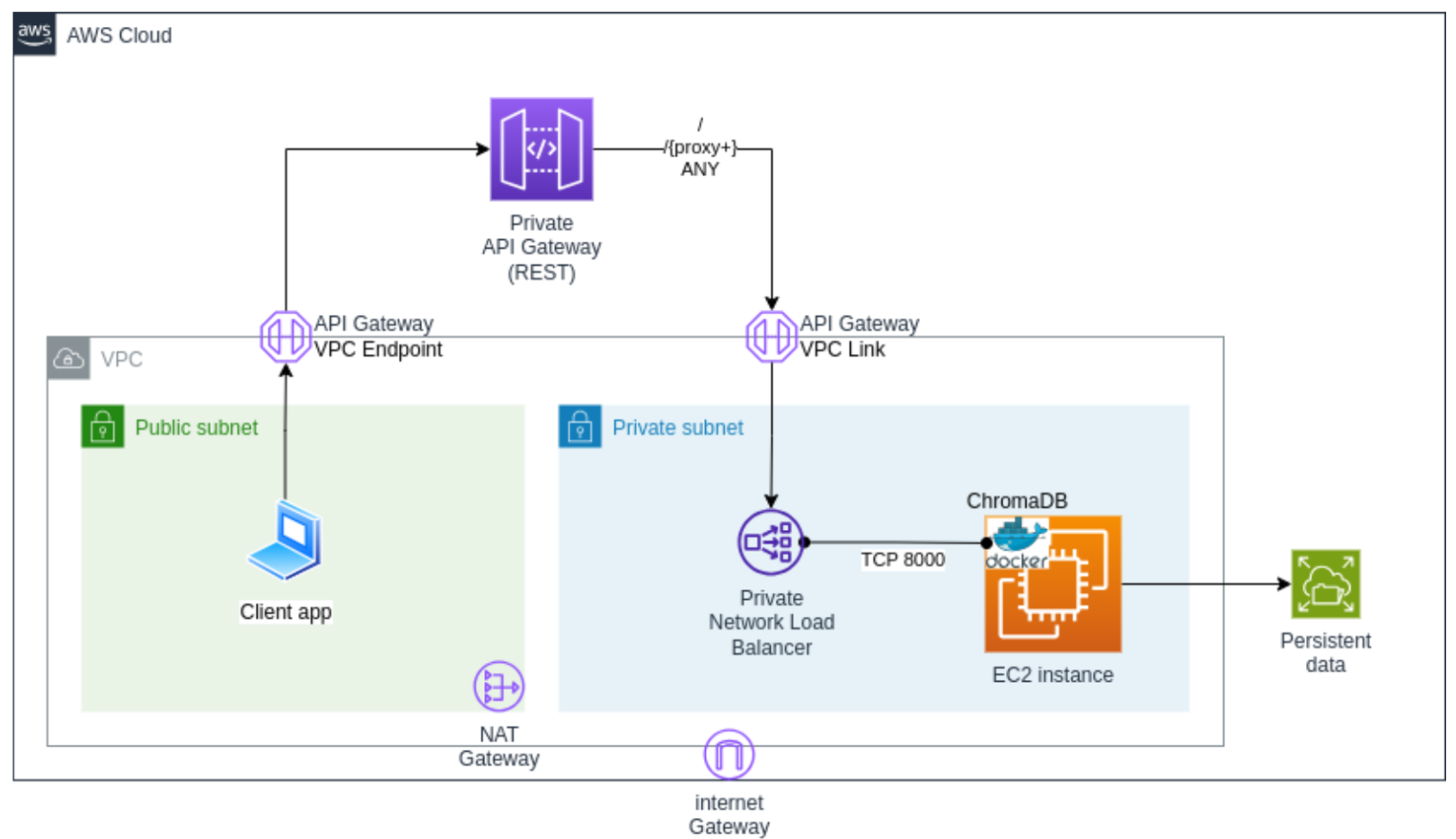
Notice that the API Gateway resources are running apart from the VPC environment, requiring the addition of a VPC endpoint and VPC link on the infrastructure to enable communication between the API Gateway resources and the other resources from the solution. The goal is to deploy all resources using the most basic options possible, allowing anyone to improve and adapt the solution to their requirements.
Coding the solution with CDK and Python
We can understand the difference between CDK and Cloudformation by creating the initial resources of our solution, but before writing a single line of code we will need to go through the basic requirements:
- An AWS account with valid credentials. There are several options for that so we won’t cover the steps in this article.
- CDK relies on Node.js regardless of the language being used to create the stack code. I use nvm to install node 18.16.0 on my machine and recommend this freecodecamp.org tutorial to anyone who doesn’t have experience with this kind of installation.
- An IDE app of choice for coding tasks. I use VSCode with the AWS toolkit plugin daily, and it works really well, especially for checking the command documentation and code completion. Adding CodeWhisperer makes the whole thing nearly perfect, but it’s not required.
- Python 3.7 or later including pip and virtualenv.
Now let’s create the most basic VPC resource in our code and see how this translates to a complete Cloudformation stack code:
from aws_cdk import ( |
Running “cdk synth” on the code above will generate a complete Cloudformation stack code with 330+ lines and 17 resources as listed below:
(.venv) matheus.santos@8100EliteSFF:~/Projects/apigatewayapp$ cdk synth | grep “Type” |
It’s true that the last 5 resources aren’t really necessary to create a basic VPC, however creating such code using Cloudformation is indeed more complex.
Conclusion
At this point, we could go ahead and deploy the stack in our account, but let’s examine what we have created so far and also add some required resources to make our cloud network environment complete before moving to the other resources.
We will pause this journey, for now, so you can take a breath and watch the view. In the next article, we will add all resources to the stack code, explaining how they work and communicate with each other, so don’t miss it!



