TL;DR:
Evaluating AI agents is the first step in achieving AI excellence. Modern evaluation frameworks measure capabilities, domain performance, generalist reasoning, and methodology to ensure reliability, safety, and real-world business value.
Table of Contents
Getting agentic AI into the real world isn’t just about building clever systems, it’s about making sure they deliver value where your business needs it most. In this blog series, I break down the practical steps that help companies move from AI hype to genuine impact, tackling everything from evaluation to ROI, governance, and scaling. To kick off this series I take an honest look at evaluation, not as a box to tick, but as a vital process that keeps your AI efforts firmly grounded in solving real problems
Starting with strong evaluation means you focus on what matters early: connecting your agent’s abilities with your goals, spotting gaps before they become issues, and setting up your AI for real-world success.
Current State of the Art Evaluation Techniques
Modern AI agent evaluation has evolved from simple accuracy-based metrics to comprehensive, multi-dimensional frameworks that assess agents across four critical axes.
- What capabilities are being tested (fundamental capabilities)
- Where those capabilities are applied (application-specific tasks)
- How broadly agents can reason across domains (generalist reasoning)
- How the evaluation itself is conducted (evaluation methodologies).
Fundamental Agent Capabilities Evaluation
The first dimension focuses on core capabilities that underpin all Agentic AI functionality, regardless of domain or application. Recent surveys identify foundational capabilities needing specialised evaluation approaches based on a multi-dimensional assessment framework:
- Planning and Multi-Step Reasoning: AI agent evaluation has advanced with frameworks like PlanBench. This reveals that current models excel at short-term tactical planning but struggle with strategic long-horizon planning. AutoPlanBench focuses on everyday scenarios and addresses complex and real-world planning challenges.
- Function Calling and Tool Use: evaluation evolved from simple interactions to multi-turn scenarios. The Berkeley Function Calling Leaderboard (BFCL) tracks function calling capabilities. ComplexFuncBench tests implicit parameter inference. StableToolBench creates stable API simulation environments.
- Self-Reflection benchmarks such as LLF-Bench evaluate agents’ ability to improve via reflection.
- Memory evaluation requires comprehensive benchmarks that test long-term information retention.

Application-Specific Evaluation Advances
The second dimension examines how fundamental capabilities of Agentic AI translate to specialised domains, where AI agents must navigate domain-specific constraints, tools, and success criteria.
- Web Agents evaluation has shifted to interactive, high-fidelity benchmarks like WebArena . Other leading frameworks include WorkArena for enterprise tasks on ServiceNow, ST-WebAgentBench, which emphasise safety, trust, and complex, policy-constrained interactions.
- Software Engineering Agents are tested using SWE-bench, TDD-Bench Verified, and ITBench. These evaluate code fixing, regression testing, and incident management in realistic engineering and IT environments.
- Scientific Agents are assessed with unified frameworks like AAAR-1.0, CORE-Bench, and environments such as DiscoveryWorld. These focus on rigorous, real-world reproducibility, end-to-end scientific discovery, and domain-expert validation.
Generalist Reasoning Evaluation
The third-dimension tests AI agents’ ability to operate effectively across domain boundaries, synthesising knowledge and adapting problem-solving approaches without domain-specific training.
- Cross-Domain Competency evaluation represents a critical challenge as agents move from specialised tools to general-purpose assistants. The GAIA benchmark leads this category by testing general AI assistants on 466 curated questions requiring multi-modal reasoning across varied contexts. AstaBench evaluates comprehensive scientific reasoning across 2,400+ research tasks, measuring both cost and quality of generalist problem-solving approaches.
- Multi-Modal Integration testing examines agents’ ability to synthesise information from text, images, audio, and structured data sources. OSWorld provides scalable, real computer environments for multimodal agent evaluation, while TheAgentCompany simulates enterprise workflows that require reasoning across multiple business contexts and data types.
- Adaptability Assessment measures how well agents can adjust their reasoning strategies when encountering novel problem types or domain combinations. AppWorld creates a controllable environment with 9 apps and 457 APIs for benchmarking interactive coding agents across multiple application contexts, providing a bridge between specialised and generalist evaluation paradigms.
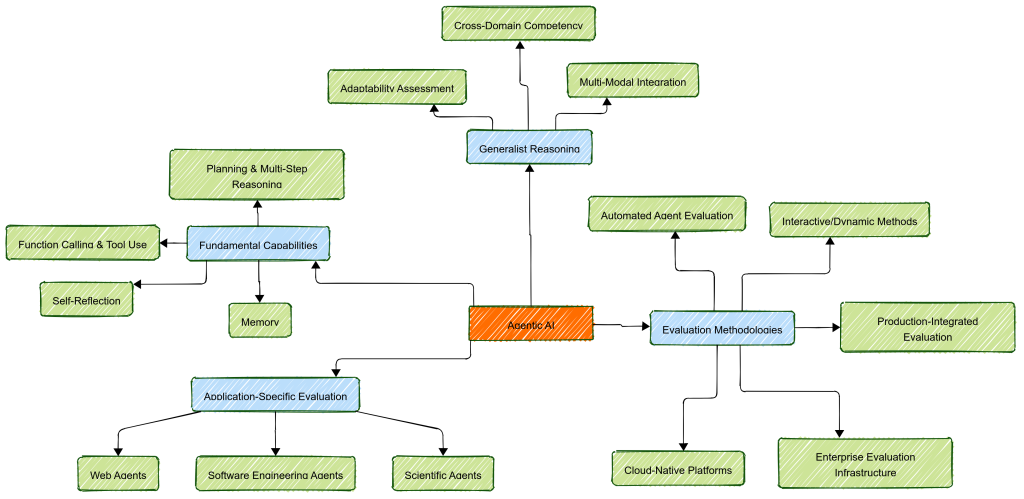
Evaluation Methodologies: The Fourth Dimension
While the first three dimensions focus on what is being evaluated, the fourth dimension addresses how AI agent evaluation is conducted. This methodological dimension has emerged as equally important as capability assessment, as traditional human-based evaluation approaches cannot scale to match the complexity and volume of modern agent systems.
- Automated AI Agent Evaluation represents the most significant methodological advancement. Agent-as-a-Judge approaches use agentic systems to evaluate other agents, providing detailed feedback throughout task-solving processes. This framework outperforms traditional single-LLM evaluation baselines by offering more nuanced assessment capabilities that can track reasoning chains and intermediate decision points.
- Production-Integrated Evaluation tools like Ragas integrate with LLM-as-a-Judge methodologies for evaluating Agents in live systems.
- Interactive and Dynamic Evaluation methodologies move beyond static benchmarks to assess agents in realistic, evolving environments. BrowserGym provides gym-like evaluation environments specifically designed for web agents, while SWE-Gym offers the first training environment for real-world software engineering agents.
- Enterprise Evaluation Infrastructure addresses the gap between research benchmarks and production deployment. DeepEval provides an open-source framework designed as “Pytest for LLMs”, enabling systematic testing of agent capabilities. LangSmith offers unified observability and evaluation platforms, while Langfuse focuses on LLM observability and agent testing methodologies with flexible frameworks for chat-based AI agent evaluation.
- Cloud-Native Evaluation Platforms such as Databricks Mosaic AI integrate comprehensive agent testing methodologies into enterprise workflows. Vertex AI provides built-in evaluation capabilities for generative AI applications, bridging the gap between research benchmarks and production deployment requirements.

Current Challenges and Future Directions
The four-dimensional evaluation framework reveals the complexity inherent in assessing modern Agentic AI. Each dimension presents unique challenges: fundamental capabilities require standardised metrics that can capture nuanced behaviours. application-specific evaluation demands domain expertise and realistic simulation environments. generalist reasoning evaluation needs frameworks that can assess transfer learning and adaptability. Evaluation methodologies must balance automation with reliability while scaling to production requirements.
Looking ahead, AI agent evaluation will become a continuous, business-driven process. It will move beyond static benchmarks to real-time monitoring. It will include adaptable success metrics, and frequent human feedback. Enterprises should get ready by building strong governance foundations and flexible testing pipelines. These foundations evolve alongside their Agentic AI systems, with teams that blend technical, ethical, and operational expertise.
For executives, the priority should be aligning AI agent evaluation with core business goals, insisting on clear oversight and measurable value. Leaders who foster a culture of ongoing evaluation and accountability will be best positioned to unlock both trust and transformative impact as agentic AI moves forward.
Summary
Evaluating AI agents is the foundation of AI excellence. A multi-dimensional approach, covering fundamental capabilities, application-specific performance, generalist reasoning, and evaluation methodologies, ensures agents are reliable, adaptable, and safe in real-world environments. In the next step of our AI Excellence series, we’ll explore ROI and cost to measure the tangible business value of AI deployments.

Distinguished technology leader with 20+ years of experience in software architecture and engineering, specialising in data and AI.