Introduction: Why PII Redaction Can’t Wait
As we highlighted in our previous post on cloud-native PII redaction, every organisation today is in the business of data. Whether it is a retailer tracking customer preferences, a bank processing transaction, or a utility provider running billing cycles, hidden inside these datasets is Personally Identifiable Information (PII): names, addresses, phone numbers, and other identifiers that put customers at risk if mishandled.
Cloud-native PII redaction has shifted from a compliance checkbox to a business imperative. Customers expect privacy-first experiences, and regulators are tightening requirements.
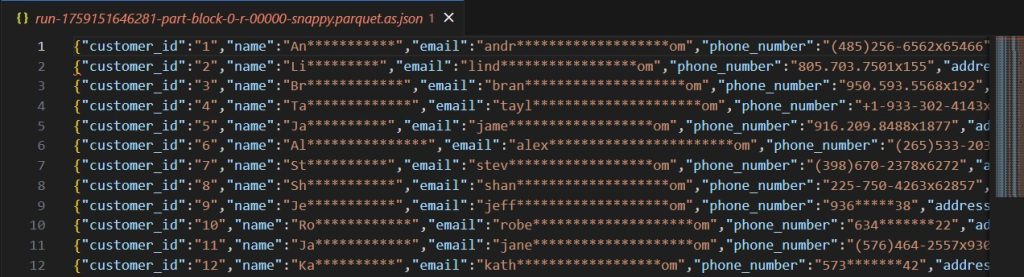
Often, this sensitive data starts in the simplest and riskiest format of all, the CSV file. Easy to create, upload, and forget, CSVs remain the backbone of many data pipelines. But they are also a major exposure point as they are copied, transformed, and shared.
In this blog, I will walk you through a step-by-step, no-code tutorial on redacting PII in CSV files with AWS Glue Studio. No scripts. No regex. Just drag-and-drop simplicity that scales with your data.
Why Redacting PII in CSV Files Is Critical
CSV files are everywhere and deceptively dangerous.
- Common: CSV exports are one of the most widely used ways to move data between systems.
- Readable: They require no special tools, making them easy to open, edit, and share.
- Risky: Their accessibility also makes them a frequent source of PII exposure when left raw or unprocessed.
For analytics, dashboards, ML models, and BI reports should never use raw CSV files that may contain personal data.
From a compliance standpoint, regulations like the Australian Privacy Act and global privacy frameworks increasingly demand that PII be redacted at ingestion. Doing so reduces both exposure and liability.
Always lock down your raw CSVs to prevent exposure.
In short: CSVs are the “low-hanging fruit” for attackers, a single misplaced file can compromise thousands of records.
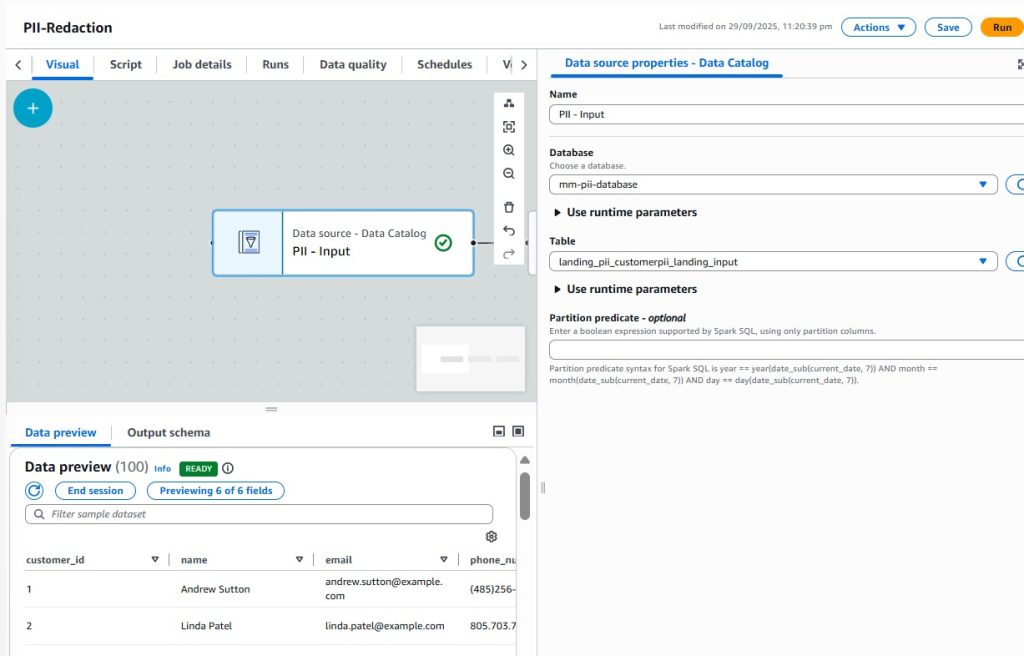
AWS Glue Studio: A No-Code Privacy Enabler
Traditionally, PII redaction required:
- Custom ETL jobs filled with regex patterns
- Third-party data masking tools
- Specialist skillsets and long development cycles
These approaches were brittle, costly, and hard to maintain.
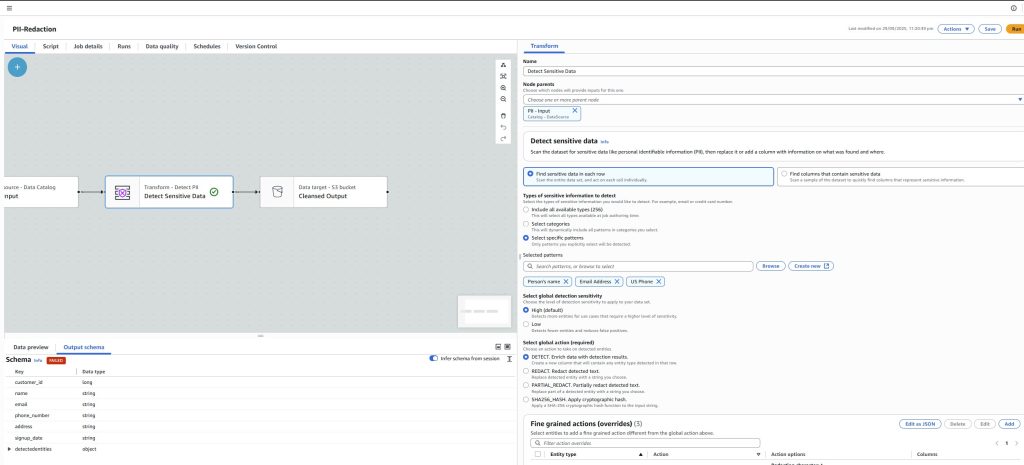
AWS Glue Studio changes the game.
With its no-code, visual interface, teams can:
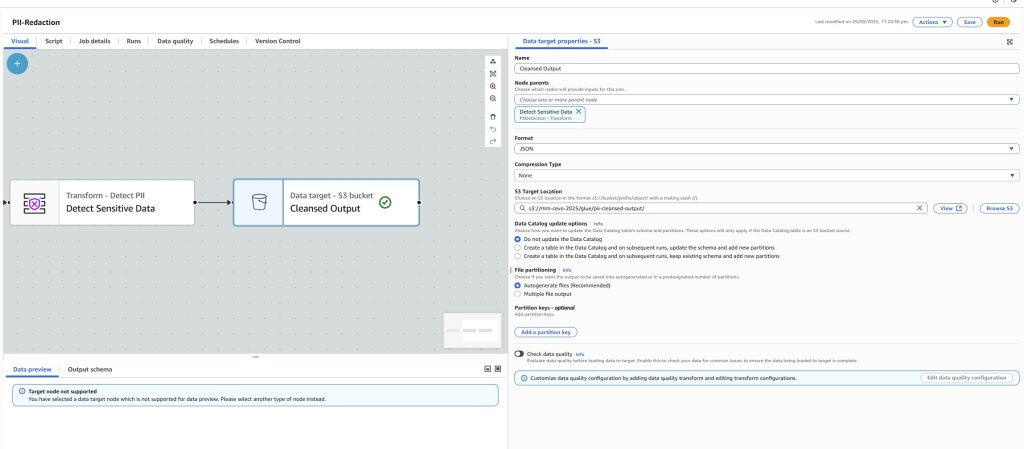
- Select a CSV source directly from S3
- Route redacted data into secure formats like CSV or Parquet
- Maintain auditability and repeatability without scripts
The result: a privacy-by-design pipeline that scales with your data lake.
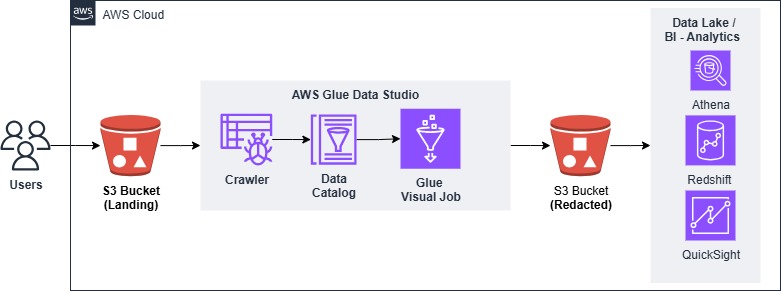
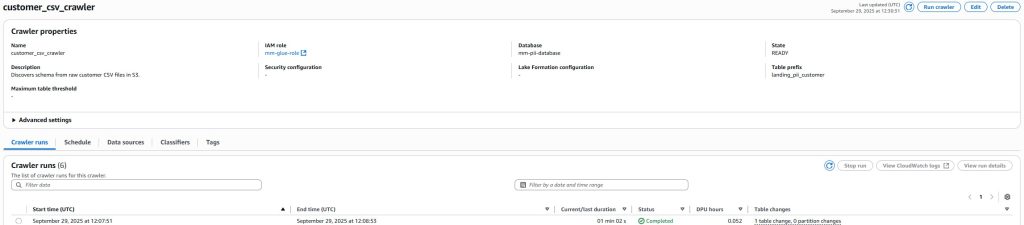
Architecture Overview
Here is the high-level flow of the redaction pipeline:
S3 Landing Bucket → Glue Crawler → Glue Data Catalog → Glue Studio Job (Detect PII) → S3 Redacted Bucket → Athena/Redshift