The Scenario
FooStore wants to build an integration that allows them to send near-real-time updates to their customers about their loyalty program; events like “customer ascended to a new rewards tier”, “customer has been gifted a discount”, as well as more mundane (but equally important) events like “customer has changed their name”
Setting aside the actual mechanics of the source (which could be a CRM of some kind), and the destination (which could be email, an app, or a digital wallet pass), let’s have a look at the middle bit where all the fun is.
An event-driven, fully serverless integration layer has been built that makes use of all-AWS technologies: EventBridge, Lambda, SQS, DynamoDB, SNS, and S3; all deployments are performed via CloudFormation, leveraging the AWS::Serverless types.
FooStore chooses to write all of its Lambdas using the Go programming language; it’s fast, strongly-typed, and makes for small function footprints.
The Challenge
During initial build-out, it was pretty easy to see what was happening in the system. There were only a few Lambdas, and the only traffic came from tests.
Forward to production, and the integration layer now has over 30 Lambda functions, multiple DynamoDB tables (some using DDB Streams to trigger other Lambdas), many different event types, and (at peak times) millions of events per minute.
It’s now impossible to say what’s happening within the system – when this particular event arrived, what happened? Where are the specific logs from the individual lambdas that processed this event, and sent their own subsequent events, and where are the invocations from those?
The Solution
X-Ray is AWS’ distributed tracing service; put basically, it allows you to instrument your code so that a single request or event from the “edge” of the system can be traced through all the intervening services; all the downstream effects of that single invocation can be identified and examined with a single click.
However, setting up X-Ray to work well can take some tweaking. Let’s get stuck in.
The First Attempt
AWS::Serverless::Function definitions allow setting the Tracing property – this turns on tracing for a function, and allocates the required IAM policy automatically. Easy, right?
A CloudFormation resource stanza for a serverless function can now look like this:
ProcessEventFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: lambdas/process-event/
Handler: process-event
Runtime: go1.x
Timeout: 3
MemorySize: 128
Tracing: Active # <--- we turned on tracing!
Events:
EventReceived:
Type: EventBridgeRule
Properties:
EventBusName: !GetAtt EventBus.Name
Pattern:
source:
- eventSourceWe deploy this and … really not much.
Yes, there are traces coming in from our Lambdas, but they’re … stunted. In the X-Ray console we see things like this:

Instrumenting the code
In order to turn the disjointed chunks into a single directed graph (for that is what a trace is), we need to add some code. The Lambda code has to be complicit; it needs to pass through the trace details. From reading the documentation of the aws-xray-sdk-go package it kind of looks like we can just do this with a pretty straightforward instrumentation call. Hooray! Minimal code changes!
package main
import (
"context"
"log"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/service/dynamodb"
"github.com/aws/aws-xray-sdk-go/instrumentation/awsv2"
"github.com/aws/aws-xray-sdk-go/xray"
)
type EventService struct {
ctx context.Context
ddbClient *dynamodb.Client
}
func (svc *EventService) EventHandler(ctx context.Context, event events.CloudWatchEvent) error {
// copy in the per-invocation context so we have our
// individual trace details
svc.ctx = ctx
// application code here, using svc.ctx in our calls to
// DynamoDB so we can pass the trace along
// ...
return nil
}
func main() {
ctx, root := xray.BeginSegment(context.TODO(), "AWSSDKV2_Dynamodb")
defer root.Close(nil)
cfg, err := config.LoadDefaultConfig(ctx, config.WithRegion("us-west-2"))
if err != nil {
log.Fatalf("unable to load SDK config, %v", err)
}
// Instrumenting AWS SDK v2
awsv2.AWSV2Instrumentor(&cfg.APIOptions)
// Using the Config value, create the DynamoDB client
svc := &EventService{
ddbClient: dynamodb.NewFromConfig(cfg),
ctx: ctx,
}
lambda.Start(svc.EventHandler)
}Specific things to note here:
- We create a root “trace context” for the entire lifecycle of the Lambda
- We override the initial trace context when each specific invocation happens, to get the specific trace reported
This looks much better!

Needles in Haystacks
There are lots of things going on in this environment; actually finding traces specific to this application is tricky. There’s a lot of hit-and-miss going on, and identifying which traces belong to our Lambdas is hard.
X-Ray allows you to create a group, based on a “filter expression”, that you can use to simplify this; the filter expression syntax is fairly straightforward, and we can just use a CloudFormation resource to define the XRay group which can apply the filter:
XRayTraceGroup:
Type: AWS::XRay::Group
Properties:
GroupName: !Sub FooStoreTracing-${Environment}
InsightsConfiguration:
InsightsEnabled: true
NotificationsEnabled: false
FilterExpression: !Sub |
resource.arn = "${FirstLambda.Arn}"
OR resource.arn = "${SecondLambda.Arn}"
OR resource.arn = "${ThirdLambda.Arn}"
OR resource.arn = "${FourthLambda.Arn}"
OR resource.arn = "${FifthLambda.Arn}"
...(the quotes are important as they’re part of the filter string)
This works! It does mean that you need to keep appending Lambdas, DynamoDB tables, and Event Bus ARNs to the end of the filter expression as you create them in the template, but that’s not a huge hassle. We can now narrow down to only traces that include resources we’ve created in our stack.
Even better, when we look at the service map in the ServiceLens console, we see only the resources we created. Note that any trace that includes any one of our resource ARNs will pass through the filter.

Finding The Outliers
service(id(type: "AWS::Lambda::Function")) { error }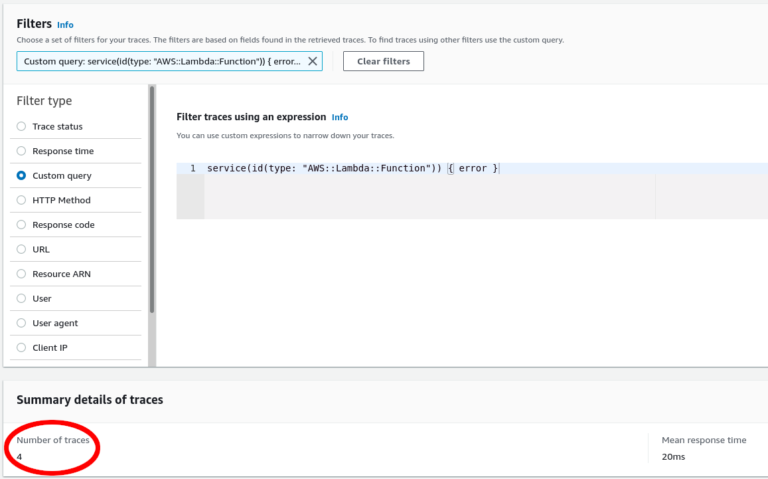
Or, we can use X-Ray Analytics to look at the distribution of response times for traces, and zoom in on those that took longer than others:

Needles amongst needles
// Annotate the ongoing trace with the customer number so
// we can find it later
// Due to limitations of the XRay SDK, we have to create a "dummy"
// subsegment to hold the annotation
// See https://github.com/aws/aws-xray-sdk-go/issues/57
// for more detail
subctx, seg := xray.BeginSubsegment(ctx, "sentinel")
if err := xray.AddAnnotation(subctx, "CustomerNumber", customerNumber); err != nil {
svc.logger.Printf("Cannot add annotation to trace: %v", err)
}
seg.Close(nil)
Anatomy of a Trace

At the top level, there’s a specific trace ID, generated automatically; each trace has one or more “segments” and each segment can have one or more “subsegments”.
Traces, segments, and subsegments have a start and end time, and can also contain annotations and other metadata about what’s happening inside a service.
Individual services and components report their trace segments and subsegments directly to the XRay service, so it can take a few seconds for a complete trace to start showing up; for a service that’s constantly active, this won’t be obvious but when you first fire it up, it can look a little odd until all the data is in and the parts are wired together.
When put together and visualised, a trace looks like this:

That’s a lot of traces
If you have an application that gets a lot of traffic, you might not want to collect every single trace – it gets expensive, generates unneeded traffic, etc; in many cases, a statistical sampling of traces is sufficient. Sampling rules are defined and maintained centrally, via the XRay console or via a CloudFormation resource; by default, the XRay SDKs collect the first request every second, and 5% of subsequent requests during that second.
An example of a sampling rule that tells XRay to report every segment for a given Lambda function in our stack is:
XRayCaptureAllMyLambdaTraces:
Type: AWS::XRay::SamplingRule
Properties:
SamplingRule:
RuleName: AllMyLambdaTraces
ResourceARN: !GetAtt MyLambda.Arn
ReservoirSize: 0
FixedRate: 100
Priority: 1000 # lower priority numbers have higher priority (P1 > P1000)State of the Art
User Interface
Right now there are 2 main interfaces for digesting and viewing XRay traces: CloudWatch Application Insights (incorporating ServiceLens), and the old X-Ray console itself. Both show much the same information but in slightly different ways; the X-Ray console includes the response-time type analytics, but you can do most of that in the ServiceLens console too.
It’s a bit confusing and awkward to switch back and forth between the two; hopefully, all the features will be collected into one, and the other deprecated.
SDK Support
There are official XRay SDKs for many languages: Go (of course), Java, Python, NodeJS, .NET (C#), PHP and Ruby; and other languages might have alpha SDKs in development (eg Rust).
Alerting
At the time of writing, only the Java SDK can emit segment metrics, so that you could set up alarms for error rates, latency, etc. Other SDKs may have this on their roadmap.
There is the “Insights” feature of X-Ray, which allows you to set up notifications for anomalies detected by the service and send them via EventBridge to SNS, an SQS queue, a Lambda, etc – but you don’t have any control of where the thresholds are, what timespan the anomaly detection runs over, etc.



