Data Build Tool (dbt) for Effective Data Transformation on AWS – Part 2 Glue

The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services – Redshift, Glue, EMR and Athena. In part 2 of the dbt on AWS series, we discuss data transformation pipelines using dbt on AWS Glue. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices.
Inside The Hive with Annabel Preacher

Learn more about Annabel Preacher’s career journey, what she loves most about working at Cevo, and her tips for other women considering entering the IT industry.
Data Build Tool (dbt) for Effective Data Transformation on AWS – Part 1 Redshift
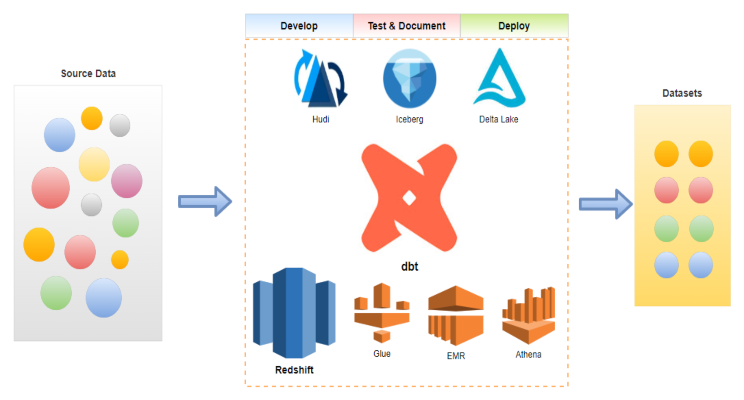
The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services – Redshift, Glue, EMR and Athena. In part 1 of the dbt on AWS series, we discuss data transformation pipelines using dbt on Redshift Serverless. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices.
Develop and Test Apache Spark Apps for EMR Remotely Using Visual Studio Code

We will discuss how to set up a remote dev environment on an EMR cluster deployed in a private subnet with VPN and the VS Code remote SSH extension. Typical Spark development examples will be illustrated while sharing the cluster with multiple users. Overall it brings an effective way of developing Spark apps on EMR, which improves developer experience significantly.
Manage EMR on EKS with Terraform

We’ll discuss how to provision and manage Spark jobs on EMR on EKS with Terraform. Amazon EKS Blueprints for Terraform will be used for provisioning EKS, EMR virtual cluster and related resources. Also Spark job autoscaling will be managed by Karpenter where two Spark jobs with and without Dynamic Resource Allocation (DRA) will be compared.
Revisit AWS Lambda Invoke Function Operator of Apache Airflow

We’ll discuss limitations of the Lambda invoke function operator of Apache Airflow and create a custom Lambda operator. The custom operator extends the existing one and it reports the invocation result of a function correctly and records the exact error message from failure.
Serverless Application Model (SAM) for Data Professionals

We’ll discuss how to build a serverless data processing application using the Serverless Application Model (SAM). A Lambda function is developed, which is triggered whenever an object is created in a S3 bucket. 3rd party packages are necessary for data processing and they are made available by Lambda layers.
Inside The Hive with Roopa Venkatesh

Learn more about Roopa Venkatesh’s career journey, her proudest moments, and what she loves about being a woman working in tech.
Data Warehousing ETL Demo with Apache Iceberg on EMR Local Environment
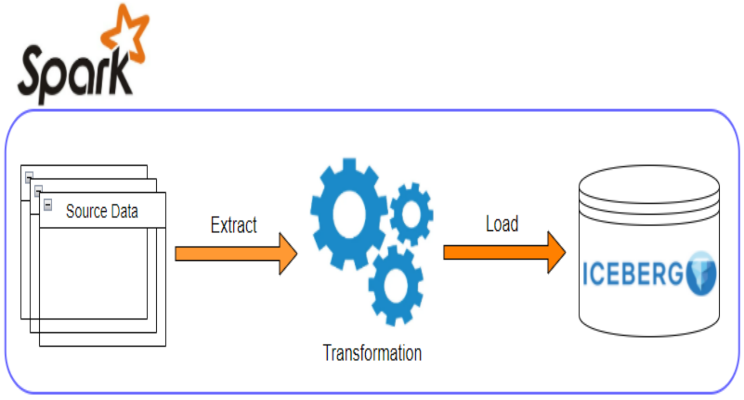
We’ll discuss how to implement data warehousing ETL using Iceberg for data storage/management and Spark for data processing. A Pyspark ETL app will be used for demonstration in an EMR local environment. Finally the ETL results will be queried by Athena for verification.
Develop and Test Apache Spark Apps for EMR Locally Using Docker

We’ll discuss how to create a Spark local dev environment for EMR using Docker and/or VSCode. A range of Spark development examples are demonstrated and Glue Catalog integration is illustrated as well.