Data Build Tool (dbt) for Effective Data Transformation on AWS – Part 4 EMR on EKS

The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services – Redshift, Glue, EMR and Athena. In part 4 of the dbt on AWS series, we discuss data transformation pipelines using dbt on Amazon EMR on EKS. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices.
Data Build Tool (dbt) for Effective Data Transformation on AWS – Part 3 EMR on EC2
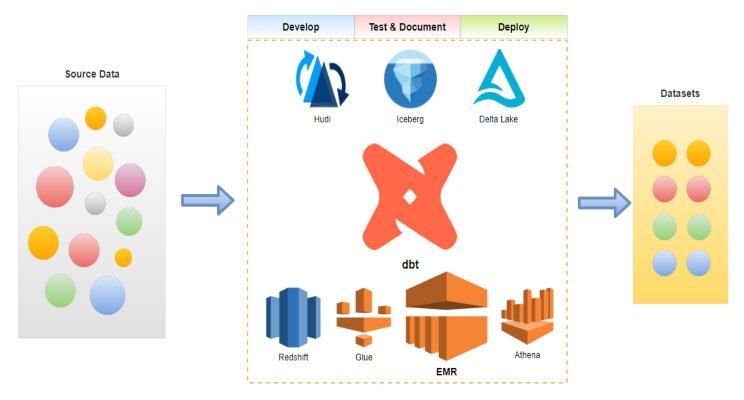
The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services – Redshift, Glue, EMR and Athena. In part 3 of the dbt on AWS series, we discuss data transformation pipelines using dbt on Amazon EMR. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices.
Data Build Tool (dbt) for Effective Data Transformation on AWS – Part 2 Glue

The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services – Redshift, Glue, EMR and Athena. In part 2 of the dbt on AWS series, we discuss data transformation pipelines using dbt on AWS Glue. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices.
Inside The Hive with Annabel Preacher

Learn more about Annabel Preacher’s career journey, what she loves most about working at Cevo, and her tips for other women considering entering the IT industry.
Data Build Tool (dbt) for Effective Data Transformation on AWS – Part 1 Redshift
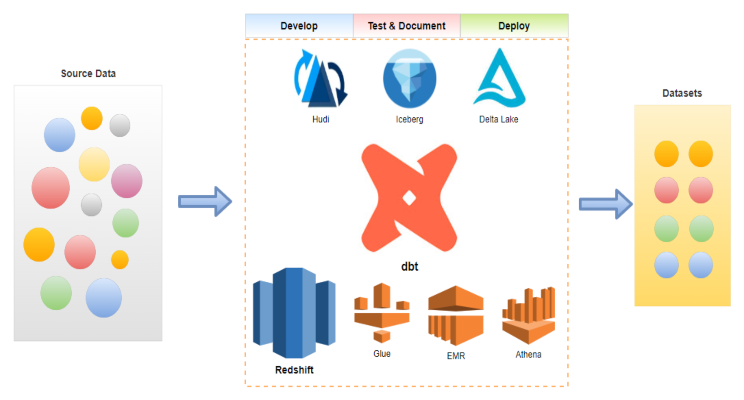
The data build tool (dbt) is an effective data transformation tool and it supports key AWS analytics services – Redshift, Glue, EMR and Athena. In part 1 of the dbt on AWS series, we discuss data transformation pipelines using dbt on Redshift Serverless. Subsets of IMDb data are used as source and data models are developed in multiple layers according to the dbt best practices.
Introduction to Amazon Honeycode – CRUD Application in Five Minutes
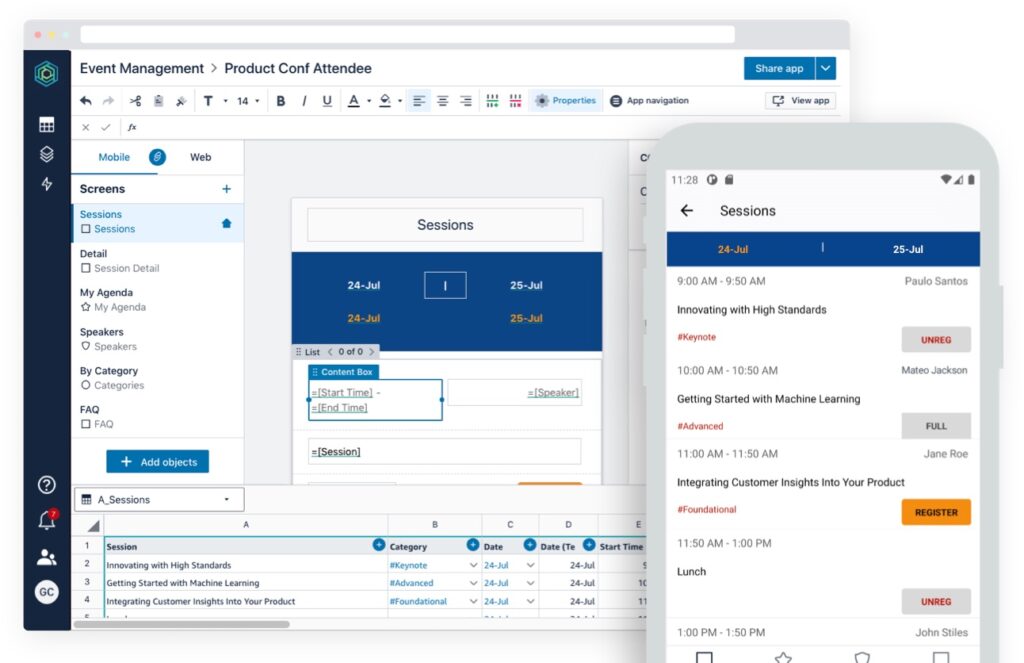
This post takes you through how to build a small CRUD application using the new Amazon Web Services (AWS) Honeycode interface.
Cevo launches Co-Create, a new program helping Australian businesses build the next generation of cloud native applications

Cevo Co-Create provides Australian businesses with a proven framework, qualified experts, and industry best practices to help them ideate, build and launch innovative cloud native applications. Comprising three distinct phases – Define, Deliver and Operate – each phase is designed to step customers through the process of end-to-end product development.
Planning account migrations between AWS organisations

As more companies move to the cloud with AWS, many are finding success in adopting multi-account architecture to house their various workloads. This article is a non-exhaustive guide on some of the steps which need to be taken before you begin your account migration journey.
Develop and Test Apache Spark Apps for EMR Remotely Using Visual Studio Code

We will discuss how to set up a remote dev environment on an EMR cluster deployed in a private subnet with VPN and the VS Code remote SSH extension. Typical Spark development examples will be illustrated while sharing the cluster with multiple users. Overall it brings an effective way of developing Spark apps on EMR, which improves developer experience significantly.
Manage EMR on EKS with Terraform

We’ll discuss how to provision and manage Spark jobs on EMR on EKS with Terraform. Amazon EKS Blueprints for Terraform will be used for provisioning EKS, EMR virtual cluster and related resources. Also Spark job autoscaling will be managed by Karpenter where two Spark jobs with and without Dynamic Resource Allocation (DRA) will be compared.